11. 机器学习 - 评价指标 2
Hi, 你好。我是茶桁。
上一节课,咱们讲到了评测指标,并且在文章的最后提到了一个矩阵,我们就从这里开始。
混淆矩阵
在我们实际的工作中,会有一个矩阵,这个矩阵是分析结果常用的。
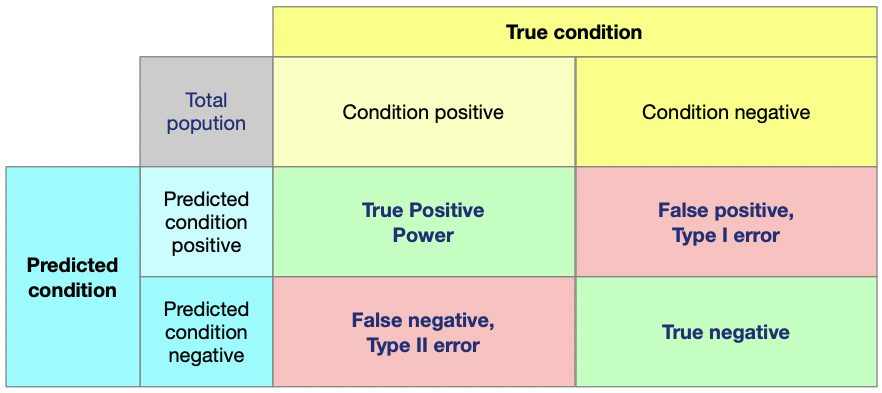
我们来看看具体是什么意思。
所谓的True condition,
指的是真实值,Predicted condition,指的是预测值。
其中行表示,Predicted condition positive表示预测值是
1,Predicted condition negative表示预测值是 0。
列表示则为:Condition positive表示真实值是 1,
Condition negative表示真实值是 0。
这样行列交叉就组成了这样一个矩阵。这个矩阵叫做混淆矩阵,英文名字叫做 Confusion Matrix.
这个混淆矩阵是什么意思呢?
True Positive 意思就是预测值是
1,预测对了,True negative意思是预测值是
0,预测对了。那相对的, False positive意思就是预测值是
1,预测错了, False negative意思就是预测值是
0,预测错了。
混淆矩阵在常见的机器学习里边是一个很重要的分析工具:
1 | |
我们可以直接看看这个方法的源码里有相关说明:
1 | |
tp 实际上是1预测值是1,tn
实际是0预测是0, fp
实际是0预测是1 fn
实际是1预测是0。
這個時候我們再回頭來看上节课结尾处的那个公式:
\[ \begin{align*} Precision & = \frac{tp}{ tp + fp} \\ Recall & = \frac{tp}{tp + fn} \end{align*} \]
很多人看到这个就有点晕,其实很简单。切换成我们刚才查看源码时查询到的就就成了这样:
\[ \begin{align*} Precision & = \frac{C(0, 0)}{ C(0, 0) + C(1, 0)} \\ Recall & = \frac{C(0, 0)}{C(0, 0)+ C(0, 1)} \end{align*} \]
tp 是实际上是 positive, 预测也是 positive. fp 就是实际上并不是 positive,但是预测的值是 positive. 那么 tp+fp 就是所有预测为 positive 的值。所以 precision 就是预测对的 positive 比上所有预测的 positive.
fn 指的是实际上是 positive, 但是预测值并不是 positive 的值。所以 tp+fn 就是所有实际的 positive 值,recall 就是预测对的 positive 比上所有实际的 positive 值。
我们这样对比着矩阵和公式来理解 Precision 和 Recall 是不是就清晰了很多?这就是 position 和 recall 根据混淆矩阵的一种定义方式。
刚刚讲了 baseline, baseline 是在做评估的时候要知道结果一定要比什么好才行。如果是个二分类问题,基本上是一半一半,准确度是 50%, 那基本上就没用。
Precision 和 recall 这两个是针对于分类问题进行评价,那我们怎么解决回归问题的评价呢?
回归问题,它也有一个 accuracy 如下:
\[ acc(y, \hat y) = \sum_{i \in N}|y_i - \hat y_i| \\ acc(y, \hat y) = \sum_{i \in N}|y_i - \hat y_i|^2 \\ acc(y, \hat y) = \sum_{i \in N} \frac{|y_i - \hat{y_i}|}{|y_i|} \]
除此之外,regression
问题里面有一个比较重要的评价方式叫做R2-scoree:
\[ R^2(y, \hat y) = 1 - \frac{\sum_{i=1}^n(y_i - \hat y_i)^2}{\sum_{i=1}^n(y_i - \bar y)^2} \]
- 第一种情况:如果所有的 y_i 和 yhat_i 的值都相等,那么 R2(y, yhat) = 1
- 第二种情况:如果所有的 yhat_i 是 y_i 的平均值,那么 R2(y, yhat) = 0
- 第三种情况:如果 R2 的值比 0 还小,就意味着它还不如我们做统计求平均值,瞎猜的结果。也就是连 baseline 都没达到。
R2-scoree 之所以常常会被用于进行回归问题的评测,主要的原因就是它防止了机器作弊。
比方说我们现在有一组数据,这组数据实际都是 0.99, 0.97, 0.98..., 这些数字都很小,而且都很密集。那么给机器使用的时候随便做一个平均值,感觉到准确度还挺高,那就被骗了。
F-score
在 precision 和 recall 之外,还有一个比较重要的内容,叫做 F-score.
首先我们要知道,precision 和 recall 这两个值在实际工作中往往是相互冲突的。为了做个均衡,就有了 F-score.
\[ \begin{align*} F-score & = \frac{(1+\beta^2) * precision \times recall}{\beta^2 * precision + recall} \end{align*} \]
\(\beta\)是自行定义的参数,由这个式子可见 F-score 能同时考虑 precision 和 recall 这两种数值。分子为 precision 和 recall 相乘,根据式子,只要 precision 或 recall 趋近于 0,F-score 就会趋近于 0,代表着这个算法的精确度非常低。一个好的算法,最好能够平衡 recall 和 precision,且尽量让两种指标都很高。所以有一套判断方式可以同时考虑 recall 和 precision。当\(\beta \to 0\), F-score 就会退化为 precision, 反之,当\(\beta \to \infty\), F-socre 就会退化为 recall.
我们一般说起来,F-score 没有特别定义的话,就是说\(\beta\)为 1, 一般我们写成 F1-score.
\[ \begin{align*} F1-score & = 2 \times \frac{precision \times recall}{precision + recall} \end{align*} \]
F1-score 是仅当 precision 和 recall 都为 1 的时候,其值才等于 1. 而如果这两个值中任意一个不为 1 时,其值都不能等于 1. 也就是说,当 2*1/2 = 1 时,F1-score=100%, 代表该算法有着最佳的精确度。
AUC-ROC
除了 F-score 之外,还有比较重要的一个概念:AUC-ROC. 这个也是为了解决样本不均衡提出来的一个解决方案。
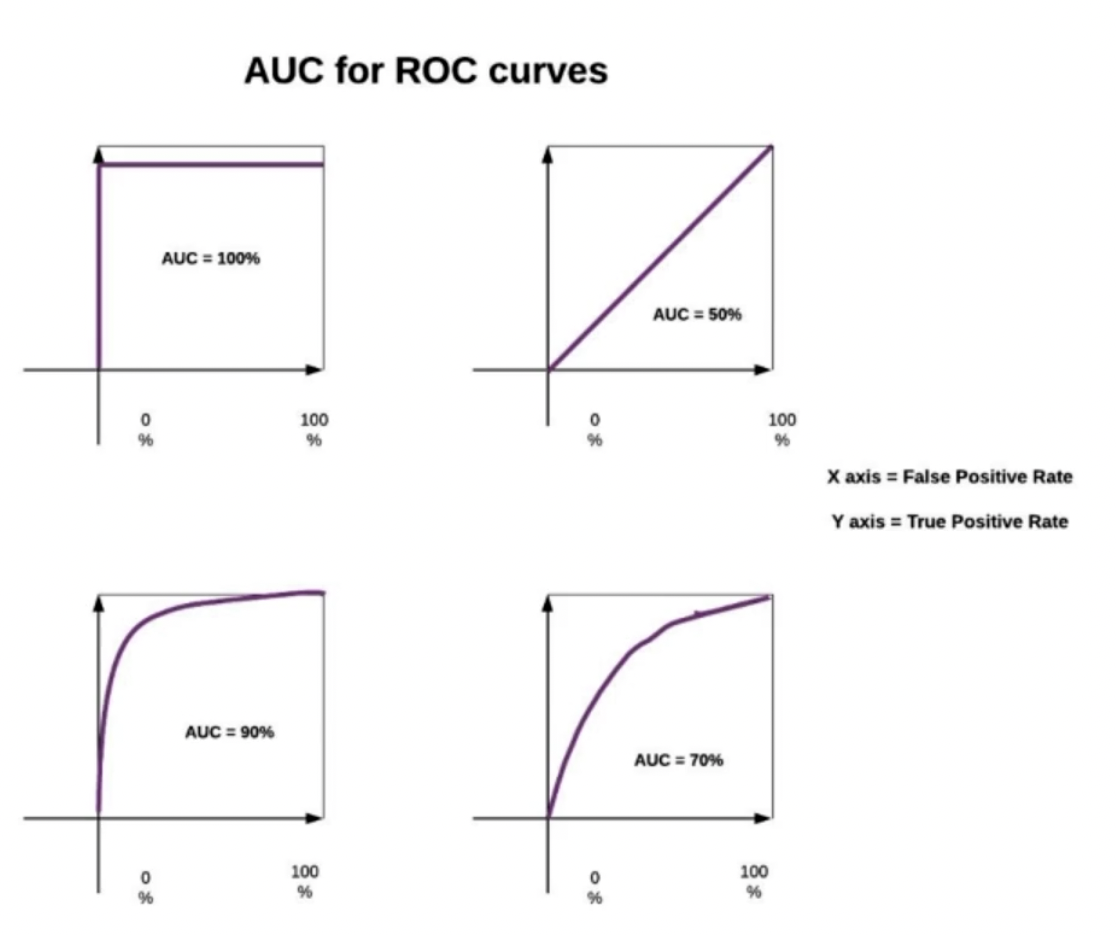
首先我们要先了解 ROC 曲线 (receiveroperating characteristic), ROC 曲线上的每一个点反映着对同一信号刺激的感受。AOC(Area under Curve), 是 ROC 曲线下的面积,取值是在 0.1 ~ 1 之间。
我们直接来看看,它在实际场景下是怎么用的。
还记得咱们在之前设定的阈值decision_boundary = 0.5,
我们就拿这个阈值来看。threshold:0.5.
在我们二分类问题中,当预测值大于 0.5 的时候,也就等于 1
了。也就是说,只要超过 0.5, 我们就判定为 positive 值。
好,现在还是的请我们劳烦了无数次的警察 a 同志来帮帮我们。当警察 a 去抓罪犯的时候,盘但一个人是不是犯了罪,他的决策很重要。在事实清晰之前,警察 a 的决策只有超过 0.5 的时候,才能判定这个人是 positive,也就是罪犯。这个时候呢,我们假设 precision 是 0.7.
现在又需要警察 b 出场了,这个警察 b 的 threshold 为 0.1 的时候,其 precision 就为 0.7. 也就是说,他预计出的值,只要大于 0.1, 就判定为 positive, 这种情况下,警察 b 判定的 precision 为 0.7.
别急,这次需要的演员有点多,所以,警察 c 登场了。那么警察 c 的 threshold 为 0.9. 也就是说,警察 c 比较谨慎,只有非常确定的时候,才能判定 positive. 警察 c 的情况,判定的 precision 也是 0.7.
好,现在我们来用脑子思考下,这三个警察哪个警察能力最强?
必须是警察 b 最厉害。
就如我们上面的那四个坐标轴,X 轴代表 threshold, Y 轴表实 positive, 当 threshold 轴上的取值还很小的时候,positive 已经很大了。那明显紫色线条和 threshold 轴圈住的区域面积越大,这个面积就是越大越好。
这就是 AUC for ROC curves, 这个主要就是为了解决那些样本及其不均衡的问题。因为样本非常不均衡的时候,position 和 recall 你有可能都会很低,这个时候就不好对比。AUC 曲线对于这种情况就比较好用一些。
其实在真实情况下,绝大多数问题都不是很均衡的问题。比方说预测病,找消费者,找高潜力用户。换句话说,如果高潜用户多就不用找了。
我们在研究 ROC 曲线实际应用的时候,依然会用到上面给大家所讲的 tp, fp, fn, tn. 这里会引出另外两个东西,TPR 和 FPR, 如下:
\[ \begin{align*} TPR & = \frac{tp}{tp+fn} \\ FPR & = \frac{fp}{fp+tn} \end{align*} \]
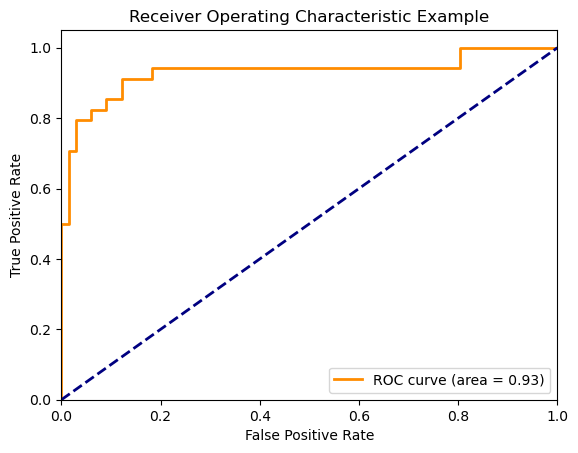
我们来看看咱们之前的这组数据的 AUC 值:
1 | |
下一节课,咱们来说一个非常重要的概念:拟合和欠拟合。
关注「坍缩的奇点」,第一时间获取更多免费 AI 教程。

11. 机器学习 - 评价指标 2

