31. BI - 从原理到实例,详解 Node2Vec 算法
本文为 「茶桁的 AI 秘籍 - BI 篇 第 31 篇」

[TOC]
Hi,你好。我是茶桁。
上一节课咱们讲了 Graph Embedding 的开山之作 DeepWalk, 结尾处说到,2 年之后推出来一个新的算法,就是 Node2Vec。这一节课,咱们就来讲讲这个 Node2Vec。
TIPS: 由于 Node2Vec 跟 DeepWalk 关联性较强,建议先去阅读上一篇 DeepWalk 的文章之后再来看本篇,理解会更清晰一些。
Node2Vec 算法
其提出时的论文为
node2vec: Scalable Feature Learning for Networks, 2016 KDD,
可以在这里查看这篇论文:https://arxiv.org/abs/1607.00653.
Node2Vec 是在 DeepWalk 之后 2 年,同样是在 KDD 上面提出来的另一个算法。
在 DeepWalk 里面采用了一个 random walk 策略,也就是随机游走的策略。那这个策略是否可以去做一些调整呢?原来随机是一个纯随机,现在我们可以采用一些固定的策略,BFS 和 DFS。
什么是 BFS 和 DFS,如果你以前学过计算机,有一些了解的话,这两个分别代表的是广度优先和深度优先,这是计算机里面的一种回溯策略或者叫搜索策略。
什么叫深度优先和广度优先?
先以深度 DFS (Depth-first Sampling) 为例,一棵树,树是由顶点开始的,你要去游走的时候也是从树上面开始,我们要去遍历这棵树,1 遍历完以后就走到 2,2 之后再接着走到他的子节点,走到 3,3 之后可能还会有 4。遍历完成以后再回缩回去,再去找另一节点。如果下方还有子节点,那就继续往下走,一直走到底,走到底之后再往回退回来一个,去找他的邻居,这样我们把它称为叫做深度路线。DFS 倾向于跑的离初始节点越来越远,反映出一个节点领居的宏观特性。
广度 BFS (Breadth-first Sampling) 的策略是不一样的,不是以深度为核心,而是以宽度为核心。走完 1 以后走到 2,2 可能旁边有个 10,就先走 10,也就是横向的去走,而不是纵向的。横向都走完以后再去往下走,走到 2 节点下面的 3。 BFS 倾向于在初始节点的周围游走,反映出一个节点的邻居的微观特性。
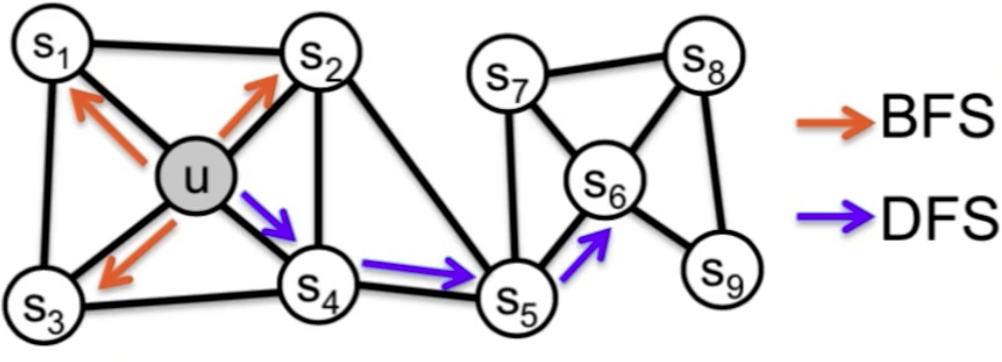
所以之前的游走是没有策略的,而现在的游走可能就会有一些策略。以 DFS 为例,可以看上图中蓝色的曲线,他走的越远越好。
如果是 BFS 为例,我们就希望走的不远,是在周围来去游荡。U 走完了 S1 再去在它周围去走 S2。所以在游走过程中,Node2Vec 是加了一些自己的思想和策略在里面。我们就来看一看这种思想和策略对于后续的表达是不是会有些帮助。
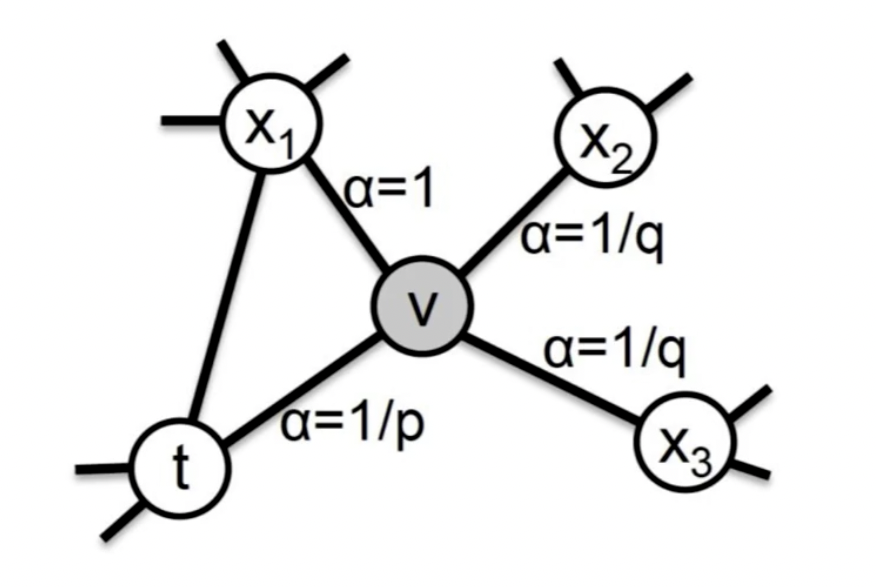
我们最初的点是 t,t 到下一个点 v,因为游走肯定是从邻居开始的。走到了 v 之后,下一步从节点 v 跳转到周围各点的跳转会有几种情况?
假设 t 这一点开始是第 0 步,这是一个原点,第一步找到了 v 这个点,之后 \(x_1\), \(x_2\) \(x_3\) 和 t 都有可能。因为 从 0 到 1 之后再回来也是有可能的。那走到第 2 步的时候,和原来的原点,第 0 步的距离有几种可能性。 为什么距离会成为核心指标,因为距离越远,它越深度优先,如果距离越近,那么就越广度优先。
其跳转概率就为:
\[ \begin{align*} \pi_{vx} = \alpha_{pq}(t, x) \cdot w_{vx} \end{align*} \]
其中 \(w_{vx}\) 代表边 vx 的权重,\(a_{pq}(t, x)\) 称为 Search bias, 一共有三种情况。
首先第一种,可能回来,从原来的原点开始走到 v 以后又回到了 t。
还有一种情况是从 t 走到 v 之后又走到 \(x_1\), \(x_1\) 和原点是直接相连的,有边的关系。
还有一种可能性是从 v 走到 \(x_2\) 和 \(x_3\),不过这两个点和原点是没有边的关系,是不直接相连的,距离就会越走越远。
这样,第 2 步的点和第 0 步的原点过程,它的 distance 就有 3 种可能性,分别是 0、1 和 2。
\[ \begin{align*} a_{pq}(t, x) \begin{cases} \frac{1}{p} \qquad if \quad d_{tx} = 0 \\ 1 \qquad if \quad d_{tx} = 1 \\ \frac{1}{q} \qquad if \quad d_{tx} = 2 \end{cases} \end{align*} \]
这三种可能性我们可以给它设定一定的概率来去控制,是更倾向于往外走还是往里走。
如果要深度优先,跑的越来越远,这应该是第 3 种可能性,\(d_{tx} = 2\)。 如果 \(d_{tx} = 0\) 就是走来走去,它会更接近于周边的一些邻居的一些特点。通过概率就可以把游走策略进行指定。
在设置过程中,因为有三种距离的可能性,如果要设置三个参数比较麻烦,干脆就做了一个归一化的处理,把中间那个参数当成一个标准。
第一种是 \(\alpha = 1/p\), 第二种是 \(\alpha = 1\),最后一种是 \(\alpha = 1/q\)。 \(1/p\) 就是 \(d_{tx}=0\) 的情况,1 就是 \(d_{tx} = 1\),那 \(1/q\) 就是 \(d_{tx} = 2\) 的时候。
假设一个场景,图有可能会很大,就相当于你开了一艘船在茫茫大海之中,如果在海上去开船方向感是非常重要的。随机的走法实际上也是可以有两种特点,第一种有点像郑和下西洋去发现新大陆,如果要走的更宏观一点,了解更多的世界,那应该是哪一种策略,是用 BFS 在中间游走还是用 DFS 去远处游走?
在海面上去做这样的一个采样,想要让这样的一个采样去学出来图中的一个宏观特征。宏观特征就是个骨架特征,从整个的架构上面看起来会更清晰。那我们如果想要这样一个特征,那肯定是 DFS。因为它走得越远骨架就越清晰,越明朗。
现在换一种扫描形式,如果想取微观特征,把周围的邻居看的更仔细。我不关心还有哪些未来的世界,只看家门口。那就应该是 BFS,周边特征。
所以不同的策略其实得出来不同的特征,可以是看宏观的部分,也可以看微观的部分。就像看一张地图,大家都用过高德地图或者是百度地图,你可以把这个地图放的缩小一些,这样宏观特征就出来了。因为你走的非常远,可以看到面积,广度很大。你可以把它拉的稍微开一些看它的局部,看它的细节,把它放大、放大、再放大,这样我们就看它的周围那些特点。
Node2Vec 就是发现了这样的一种游走的策略,并且通过 p 和 q 来去刻画,到底是探索世界,还是在家周围附近溜达。
怎么去刻画呢?p 和 q 是两个超参数,这两个超参数分别称为「返回概率」(returen parameter) 和「出入参数」(in-out parameter)。
如果 p 比较大,大于 q 和 1 的最大值 (\(p > \max(q, 1)\)), 这里是往回走的概率就低。我们之前讲过 \(\alpha = 1/p\), p 比较到的话,那分母大了,整个概率就会变小,所以往回走的概率是比较低的,那么它是属于 DFS 特性。也就说它尽量不往回走是往外走。
同理,如果设置调节出来 p 比较小,小于 q 和 1 的最小值 (\(p < \min(q, 1)\)),比较小的情况下除完以后就大,就会拉回来,那么采样会倾向于返回上一个节点,也就是更容易在起始点周围的节点来回转悠。
再去看一下 q,q 跟刚才说的 p 也是一样的,也是个调节的参数。如果 q 比较大,\(q > 1\),\(1/q\) 应该就会比较小, 比较小的话是往里走,就不太容易跑出去。就是 BFS 的一个特征。
相反,q 比较小就会倾向于往外走,体现出深度的特点。
说这么多其实也就是想说明,p 和 q 是可以调节开船的一个特点,如果你是个船长的话,那这个特点就是你到底想去看宏观的还是看微观的。
那我们现在可以来思考一下,DeepWalk 和 Node2Vec 这两种方式来进行学习,谁更容易把特征学得更好。哪种方式的 Embedding 策略会更优秀一些。
这个就是要看最终的一个评价标准,我们会有一些任务去做打分,一般可以用分类任务。这两者之间其实是有关系的,如果仔细去斟酌会发现,DeepWalk
本身是 Node2Vec 的一种特例,当 p = 1,q = 1
的时候,它就是一个纯随机游走,游走方式就等同于 DeepWalk
的随机游走,邻居的可能性都是一样的。
那么 p 和 q 都为 1 的情况下,Node2Vec 就退化成了 DeepWalk。也就是说,当把它们都设为 1 的时候,它本身的策略就是 DeepWalk 的策略。
超参数在 Node2Vec 的过程中是可调的,可调就给了你更多的可能性,可以调节你的模型让你模型的效果会更好。通过 p 和 q 来控制游走的方向,从而更好的去把一张图的宏观特征或者是微观特征学到。通过调节 p,q 超参,可以调节 BFS,DFS。
如果宏观特征对于分类结果有价值,就可以 q 小一点,把这个特征学出来,这样分类结果就会好。如果微观特征对分类结果有价值,就可以让 q 稍微大一点,最终可以对分类结果会好一点。通过调参数的方式就可以得到更好的一个结果。对 Node2Vec 通过 p 和 q 来进行调节,它可以取得的效果比 DeepWalk 要好。
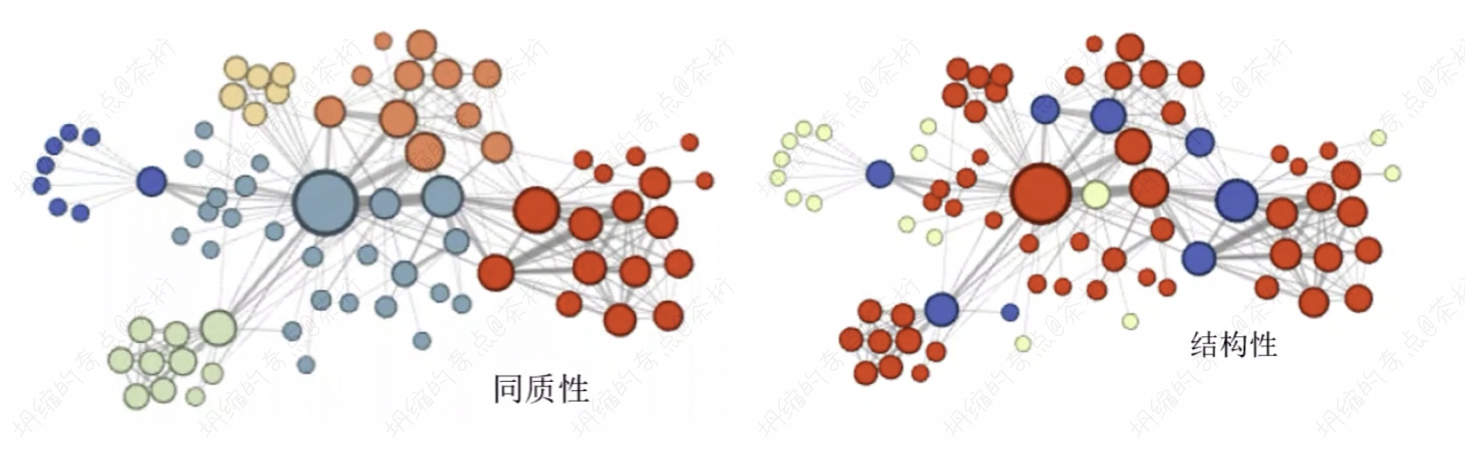
Node2Vec 算法可以挖掘网络中的同质性 (homophily) 和结构性 (structural equivalence)。
同质性,指的是距离相近节点的 Embedding 应该尽量近似,节点 u 与相连的电 s1, s2, s3, s4 的 embedding 表达应该是接近的。
结构性,指的是结构上相似的节点的 embedding 应该相似,节点 u 和节点 s6 都是各自局域网络的中心节点,embedding 表达相近。
这就是 2014 年和 2016 年两篇 KDD 上的 Graph Embedding 算法。这两种方式现在也是当前使用的比较多的 Graph Embedding 的策略。在微信朋友圈的广告投放中就采用了 Node2Vec 的方法来对人的特征做了一个学习。
那 Node2Vec 怎么计算?

它的计算第一步,转移概率矩阵可以提前算好。因为 p 和 q 是超参数,不同的 p 和 q 转移概率是不一样的,所以把它 p 和 q 算完以后就可以知道它到邻居的一个转移概率。
第二步是通过计算好的转移概率去进行 generate,实际上走的还是 random walk 的思路,随机游走。所以第一步是给第二步提供了策略知识。对图中的每个节点,进行 r 次随机游走得到 r 个长度为 l 的 walk,可以理解为给每个节点造句,r 个长 l 的句子,全部节点的游走合起来就得到了这个网络的语料库。
第三步,产生的这些语料,经过类似 skip-gram 的训练可以得到节点的 Embedding。
作者在论文中也详细的阐述了这个方法的好坏程度,它的对比有 DeepWalk,还有其他的一些 Embedding 的模型。
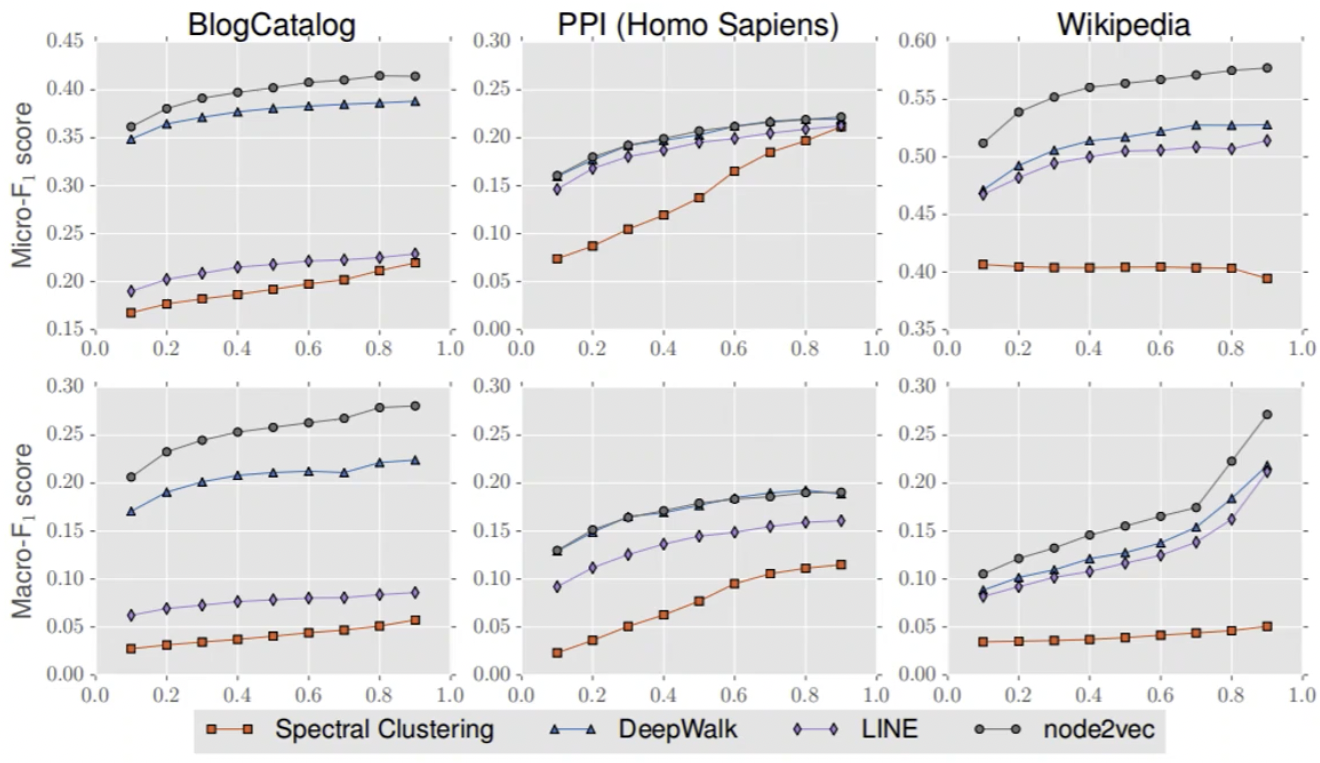
\(F_1 score\) 跟我们的 AUC 是类似的,是越大越好。这是作者跑了三组实验,可以看出来 node2vec 是最好的。
除了谱聚类,其他的算法都使用了 Embedding 这种连续的特征表示,实验结果一致的好于谱聚类。使用 Embedding 不仅可以应用于 NLP,还可以用于网络特征表达。
网络中每个节点的邻居集如何选择会很大程度的影响 Embedding 的效果。Node2Vec 的创新之处就在于提出了一种灵活的选择节点邻居的方法,实验证明比其他的方法更有效。
在这四个 Embedding 的策略过程中,node2vec 可以让模型的上限达到一个比较高的一个维度。所以在建模过程中,之前也给大家说过一句话:特征决定模型的上限,而模型最后只是把它跑成而已。
Embedding 是帮用来提取特征的,可以把它理解成是一种特征工程。特征工程后面要喂给分类方法,可以采用神经网络或其他不同的方法,比如说用 FM 等等。所以 Node2Vec 这种特征工程就可能让模型的上限达到更高的一个高度。
在平时的时候我们可以直接调包,在 Github 里面可以找到 Node2Vec 的包: https://github.com/eliorc/node2vec
1 | |
它的输入有 graph 原始的数据, dimensions
是我们要去确定的一个 Embedding 维数,默认它是 128。
walk_lengths 是随机游走的长度,num_walks
是随机游走的次数,workers 是并行线程,默认为 1。
定义好模型之后就可以去 fit 了,fit 实际上就是训练过程。
1 | |
在 fit 过程中要指定窗口大小,指定窗口参数大小是因为它的本质还是调了一个 word2vec,它的 Embedding 学习都是通过句子的方式,Word Embedding 来学出来的,所以它有一个 window。
咱们还是以美国大学生足球队为例,看一看该怎么去做这个例子。
我们还是一样,先去读取那个 gml 文件:
1 | |
然后直接调用 Node2Vec 这个包,创建咱们的模型:
1 | |
制定好参数,model 就创建好了。这个创建过程它还没有去你和训练,只是把模型的准备工作准备好了。后面 fit 过程中,就给他设置训练的一些参数:
1 | |
训练完成以后,我们就可以得到 word embedding, 词向量:
1 | |
wv 代表的是
word2vec,从单词的词向量里面去做一个计算,去计算
EastCarolina,最后打印出来最接近的是 Memphis, Cincinnati
等等。
也可以把它的都打印出来,最后采用 PCA 的方式,跟上一节课的过程也是一样的,把它放到一个二维的平面轴里面,这样就可以一次性的看出来 115 支球队哪些球队之间是更加的接近一些。
1 | |
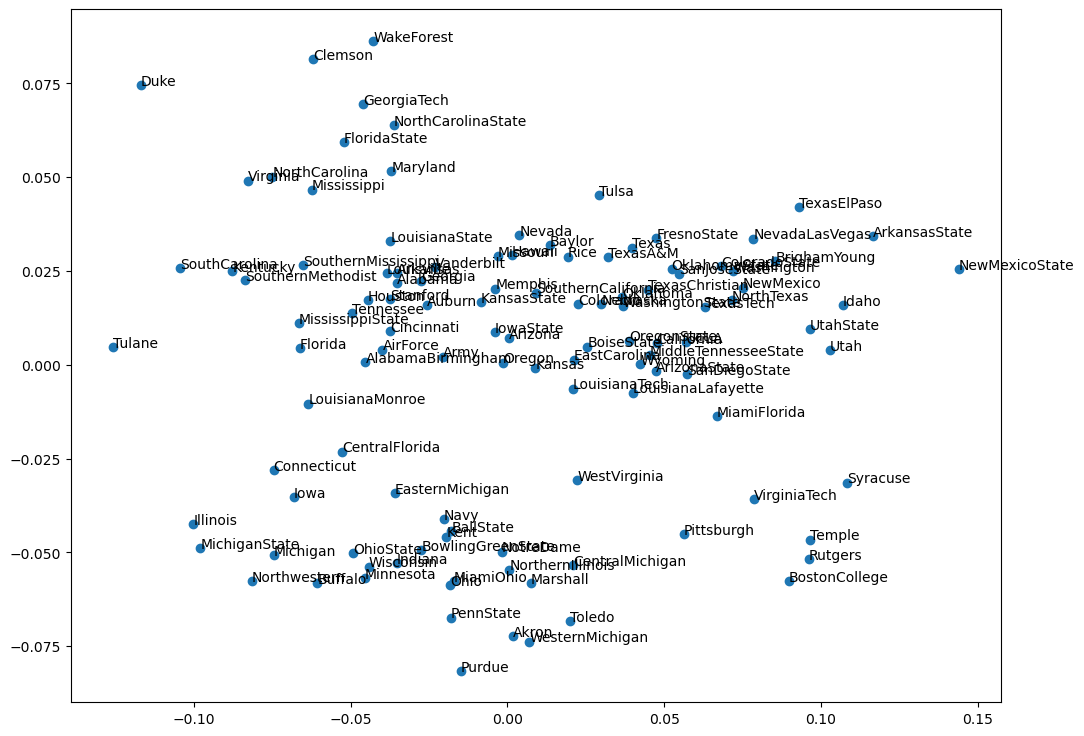
可以看到现在得到的这个结果跟之前的结果还是有区别的,跟咱们上一篇 DeepWalk 之间还是有区别的。似乎显得更加的紧密一点,这跟 p 和 q 的设置有一些关系。当然我们可以把 p 和 q 都改成 1,改成 1 以后看看有没有一些变化。
1 | |
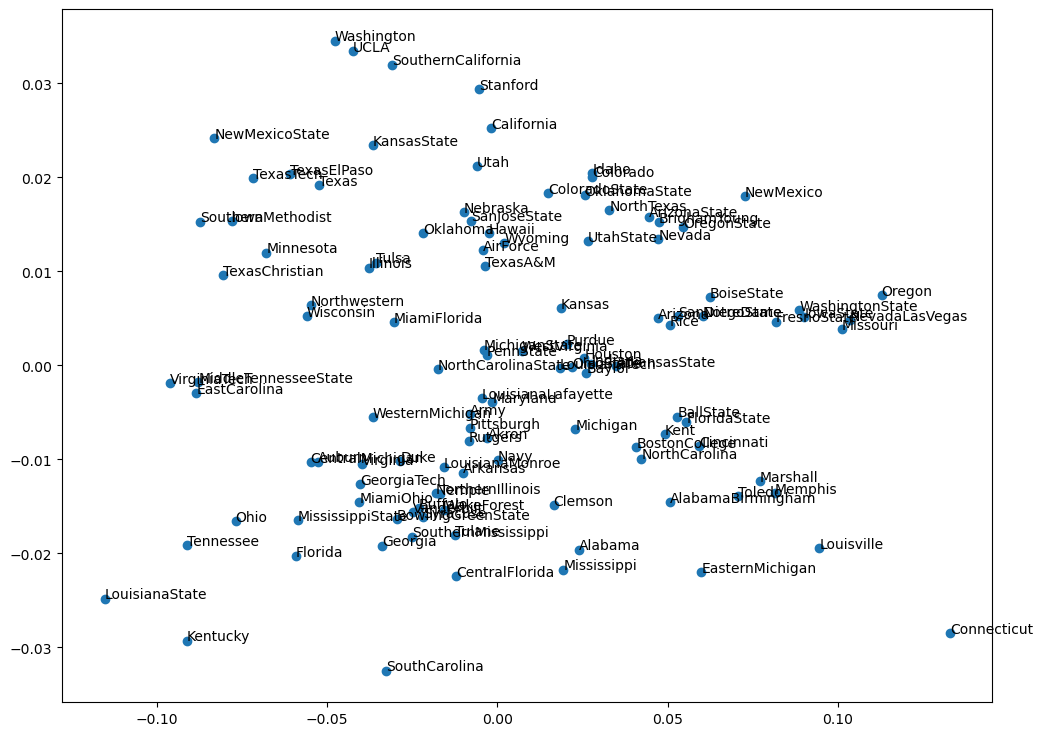
改成 1 以后的跟我们使用 DeepWalk 的结果就稍微接近一些。一眼看过去的长的样子就会比较像。
这是因为改成 1 以后的,Node2vec 就退化成了 DeepWalk,完全随机的一种游走方式。所以超参数去调节可以去看它不同的特征,这个特征看是不是对后续的分类结果会更有效一些。所以从实验的这个例子上可以看到,node2Vec 其实是更有可能找到更好的一个结论。就是让任务最终的分类准确性可以达到一个更高的一个成果。
集合包: graphembedding
接下来,咱们来看一个 Graph Embedding 的算法集合包,介绍一个 Graph Embedding 工具: https://github.com/shenweichen/GraphEmbedding。
这个工具就是 DeepCTR 的作者,是阿里的一个同事写的包。这里面包含了多种 Graph Embedding 算法,包括 DeepWalk,Node2Vec 等等。它是对特征来做抽取,可以用于我们后续的推荐系统。
这个同事,也就是这个作者比较勤奋,把以前开放的一些重要的论文都自己做了一个实现,在 Graph Embedding 里面就包含了这些算法和应用。
具体我们就可以直接使用 Graph Embedding 这个包,然后从它的 Models 里面 import 相关的算法包:
1 | |
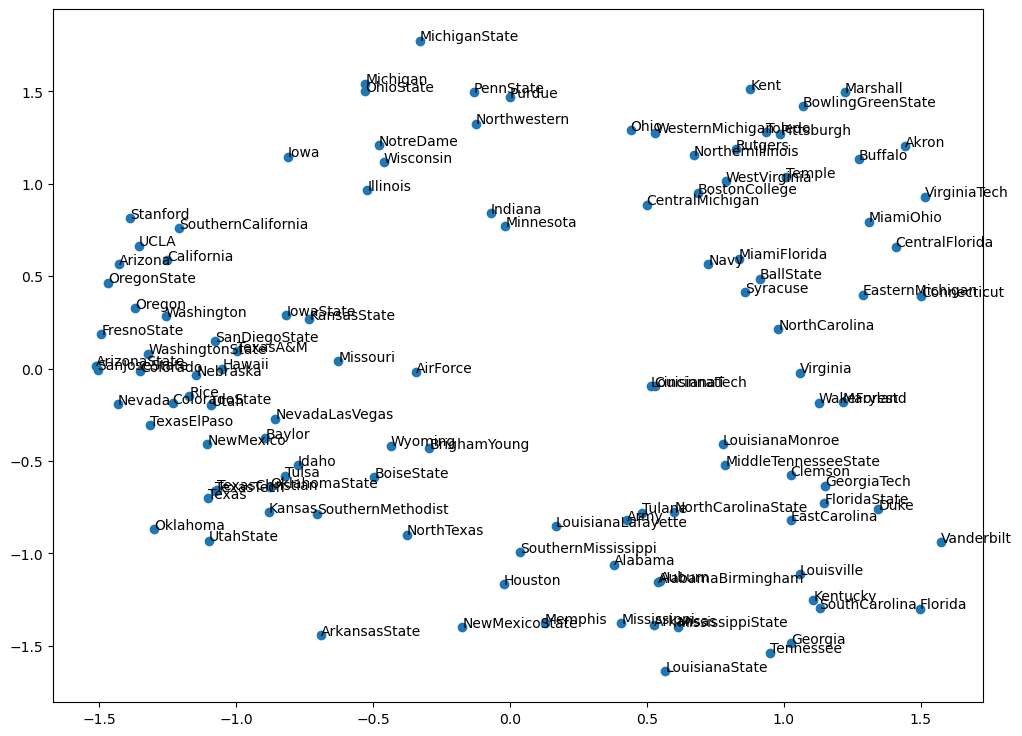
导入包之后,之后和我们之前讲解 DeepWalk 以及 Node2Vec 的用法是一模一样。最后是一张用 Node2Vec 的结果生成的图:
这个插件不能直接使用 pip 或者 conda 进行安装,需要 clone 到本地候使用
python setup,具体的安装方式在包的 Github
上作者有详细的写明,大家可以去看看,自己尝试着用一下。
其实调包不是难点,难点是在于前期的数据转换。能不能把你的数据看成一张图,把这个图喂给这个包,然后这个图里面的所有顶点就可以打印出来了。
从原始数据构造图的练习
接下来,咱们完成一个完整的练习复习一下学过的 DeepWalk 和 Node2Vec,其实我们主要是要来看一下 Graph Embedding 该怎么实际应用。
这个练习中咱们用到的是 seealsology, 它是一个页面分析的工具,可以让你找到跟指定页面相关的一些 Wikipedia。
现在是已经拿到了源数据 seealsology-data.tsv,
tsv 是一种文件的格式,它跟 csv
是一样的,t 就是 table 的含义,所以它中间的空格是用 table
来去做一个分隔符。当然你可以用我给到的这个数据源,也可以自己去找一个你想要分析的页面去重新生成一个数据,工具的地址是:https://densitydesign.github.io/strumentalia-seealsology/
咱们现在用的这个数据存储了三个列,Source, target, Depth 这三列。有了这三列以后我们可以使用 Graph Embedding 对节点进行策略的一个学习。
首先 source 和 target 就是一个图的关系,有了图的关系以后你可以知道谁和谁会更接近一点。所以主要的核心是要求 Graph Embedding,然后再把这个数据去给它呈现出来,可视化,使用 PCA 呈现在二维平面上。
可以采用任何的方式, DeepWalk 或者是 Node2Vec 都是可以的,把这个数据拿过来一起来去做一做。
数据在仓库内,大家可以自己去 pull 下来。
首先,我们需要对数据进行读取:
1 | |
读取的时候我们要在后面加上sep='\t',
原因前面也说了,tsv是一个 table 来做分隔符的源文件。
读出来之后能看到,大概有 3,700 多行。每一行都告诉你一个边的关系,哪一个单词和哪一个单词之间。因为 Wikipedia 有链接的关系,所以这两者之间它是有关系的,我们就可以给它做一张图。
下面要去做的事情就是在原有的这张图里面去构造一张图,原有的这样一个 DataFrame,还用 networkx,可以去从 pandas 里面生成 edgelist。
1 | |
把这个 df 数据喂给它,然后指定一下 pandas 里面的两个列,一个是 source, 一个是 target。用的是一个无向图,构造好图 G。打印一下结果可以看到,这是 networkx 的一种数据的格式。
构造完图以后就可以用 DeepWalk
来进行随机的游走,这个就和我们之前课程里所讲的都一样了,这里我还是使用了
graphembedding
这个包里的集成算法,参数也都是类似的,直接把代码拿了过来并未做更改。
1 | |
然后训练一下
1 | |
我们可以得到它的 Embedding,可以把 Embedding 打印出来看看:
1 | |
用 len 去查看一下,可以看到这个 embeddings 的长度是有 2399,和之前咱们例子里用的数据就多了很多,之前那个美国大学生球队的例子里,长度是 115. 可以预见的是,咱们的图在生成出来之后,应该是不太容易观看。
接着我们来绘制节点向量图,还是用上节课中写的那个方法。
因为原来维度可能会会很大,单纯去看它也很难去看,这 100 多维无法进入可视化,所以给它嵌入到 PCA 的两维空间里面去,信息会有损失但整体上可视化的效果会更直观一点。
1 | |
这里我调用的时候传入的是 results,用的是训练候的数据,当然你也可以不通过训练直接传入,不过我们就要用另外一个方法:
1 | |
让我们来看看图是怎样的.
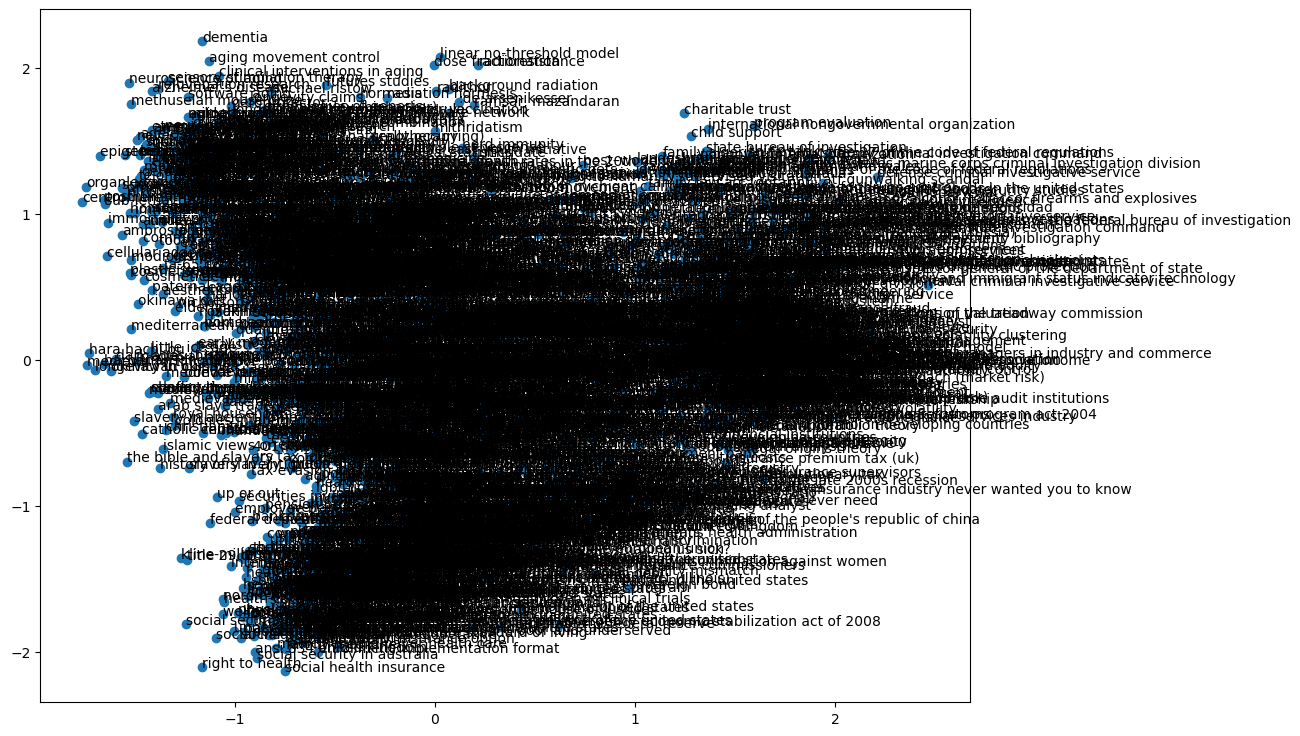
果然不是那么优美,简直就是不忍直视。因为单词的 site 会比较大,有 2399 个,可以自己来随机的抽取一些顶点。
这里就是让大家熟悉一下这个工具,在之前的课程里知道了怎么用 Deepwalk 之后,这节课咱们把内容连起来,明白如何从一个原始的 csv 文件通过 pandas 读取成 DataFrame, 然后构造成一张图,再来使用 DeepWalk 或者 Node2Vec 来完成游走。
下节课,咱们来跑一个 Project,看一个完整的推荐系统。
31. BI - 从原理到实例,详解 Node2Vec 算法

