15. 机器学习 - 支持向量机

Hi, 你好。我是茶桁。
逻辑回归预测心脏病
在本节课开始呢,我给大家一份逻辑回归的练习,利用下面这个数据集做了一次逻辑回归预测心脏病的练习。
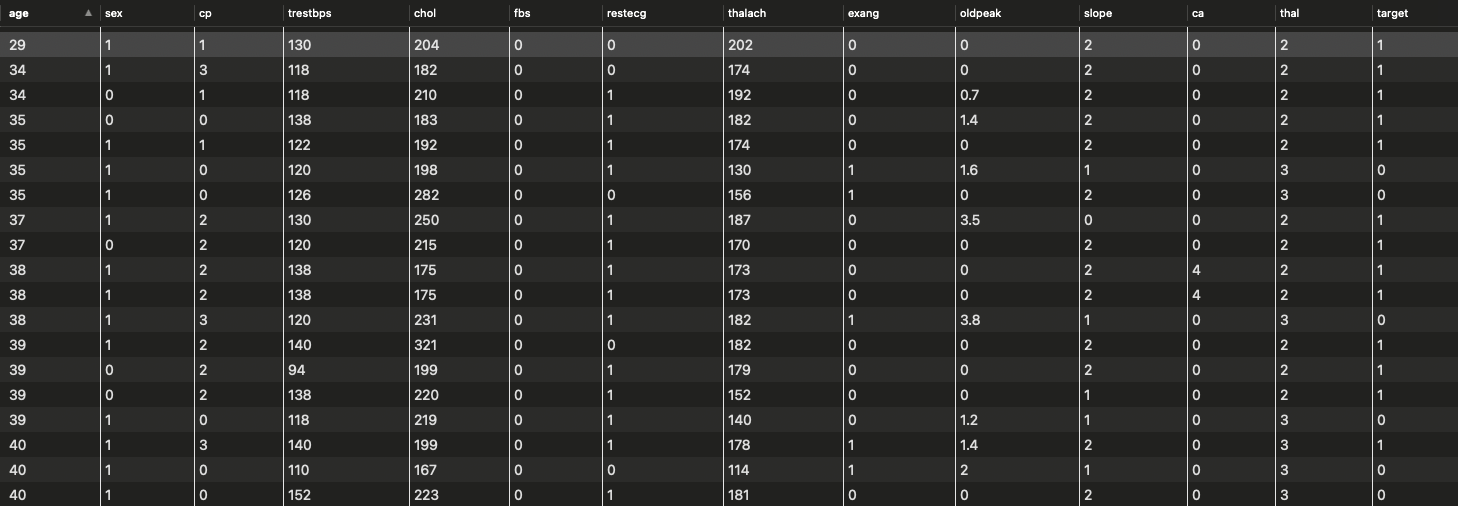
本次练习的代码在「茶桁的 AI 秘籍」在 Github 上的代码库内,数据集的获取在文末。这样做是因为我的数据集都是和百度盘同步的,很多数据集过大了,所以也就不传 Github 了。而且,我直接获取盘内同步数据也更方便。
还有一个原因,有些数据集可能以后会收费获取。
好,让我们进入今天的正课。
因为未来几节课的内容比较多。「核心基础」的这部分内容已经超出我原本的预计,咱们「核心基础」的部分刚刚过半,可是已经写到 15 节了,本来这部分内容我是想在 21 节左右结束的,所以,我们还是要压缩一下内容了。
这节课咱们还是继续讲解经典的机器学习。
支持向量机
接下来,要讲解一个非常有趣的方法:支持向量机。
支持向量机的原理其实可以很复杂,但它是一个很经典的思想方法。咱们就把它的核心思想讲明白就行了。其实我们平时在工作中用的也比较少。但是面试中有一些老一代的面试官会比较喜欢问这个问题。
支持向量机的核心思想,假如我们有两堆数据,希望找一根线去把它做分类,那么咱们找哪一根线呢?
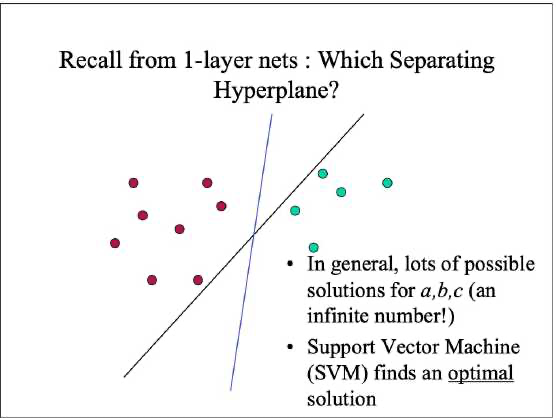
上图中,我们假设黑色的那根线定义为 l,把离这根线最近的点,也就是直线距离最小的点,找到两个这样的点定义为 P1、P2。
现在我们是希望离这个 l 最近的点,假如说是 d1,d2,那么我们希望这两个距离加起来最大:max|d1+d2|。
现在再定义蓝色的线为直线 b,那直线 b 做分类就比直线 l 要好。为什么直线 b 就比是直线 l 好呢?因为直线 b 离 d1,d2 普遍都比较远。
现在这里的演示是一个二维平面中用一根线来分割,如果是在多维空间中,SVM 的目标就是找到一个最佳的超平面来最大化间隔,同时确保正确分类样本。
假设我们有一组训练样本,每个样本用特征向量 x 表示,并且标记为正类别 +1 或负类别 -1。
我们可以表示为以下凸优化问题:
\[ \begin{align*} min_{w, b}\frac{1}{2}||w||^2 \end{align*} \]
其中对所有样本
\[ y_i(w \cdot x_i+b) \ge 1 \]
w 是超平面的法向量,b 是截距项,yi 是样本 xi 的标签,也就是 +1 或者 -1。
为了解决这个优化问题,我们引入拉格朗日乘子\(a_i\)来得到拉格朗日函数:
\[ L(w,b,a) = \frac{1}{2}||w||^2 - \sum_{i=1}^Na_i[y_i(w\cdot x_i +b) - 1] \]
然后我们要最小化拉格朗日函数,首先对 w 和 b 求偏导数,令它们等于 0,然后代入拉格朗日乘子条件:
\[ a_i[y_i(w\cdot x_i + b)-1] = 0 \]
然后我们就可以得到如下这个式子
\[ w = \sum_{i=1}^Na_iy_ix_i \\ sum_{i=1}^N a_iy_i = 0 \]
使用某种优化算法(例如,SMO 算法),求解拉格朗日乘子\(a_i\)。我们就可以使用求解得到的\(a_i\)计算超平面参数 w 和 b。
对于新样本 x,使用超平面\(w\cdot x + b\)的符号来预测其类别。
那我们讲了这么半天,都是一个支持向量机的数学演示过程,下面我们来看看具体的代码实现。
我们先来生成两组数据,这两组数据咱们让他距离更大:
1 | |
我们现在来观察以下生成的这些点:
1 | |
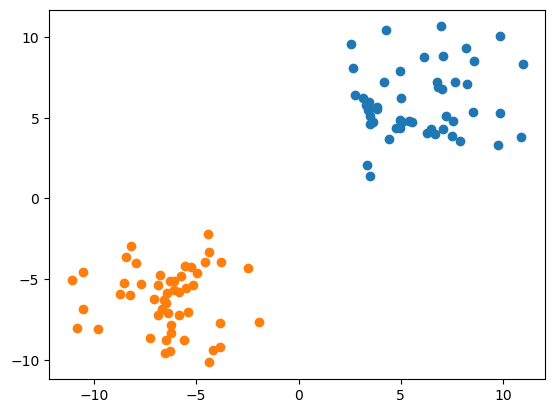
然后我们继续:
1 | |
我们就将这两组数据的第一列分别取出来了。
接着我们随机的定义一些 w 和 b
1 | |
然后我们按照之前讲的数学演示来定义一个函数
1 | |
然后我们之前从数学演示里已经知道,\(y_i(w\cdot x+b) \ge 1\), 而我们也知道这个说的是距离,也就是说,同样的$y_i(wx+b) $。
也就是说,我们要让函数 f 小于等于 -1,并且大于等于 1。当然,为了保证其被分到两边,我们将函数的最大值定义为小于等于 -1,将函数的最小值定义为大于等于 1。这样就保证 (-1,1) 之间是不存在任何函数值:
1 | |
只有同时满足这两个条件的值,我们才会留下来进行保存。我们可以定义一个变量将其保存
1 | |
在得到这些 w,b 之后,我们将这些 w,b 连起来进行画图:
1 | |
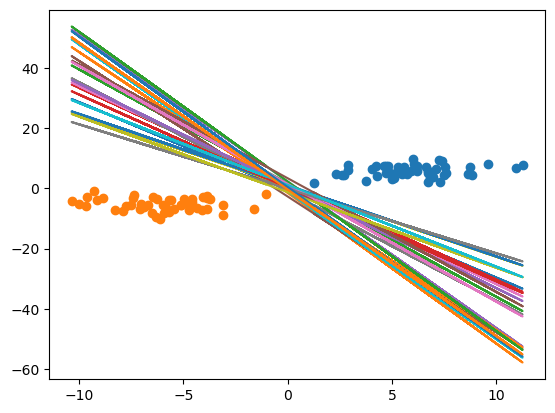
这样,我们就拟合出来了很多的曲线。这些个曲线到底哪一个是最好的那一个呢?
现在根据刚刚得到的那个结论,现在所有的\(y_i(w\cdot x_i + b)\), 那么现在其实就是\(margin = \frac{2}{||w||}\)。
那我们现在就找这个 w 最小的这个值就可以了。
1 | |
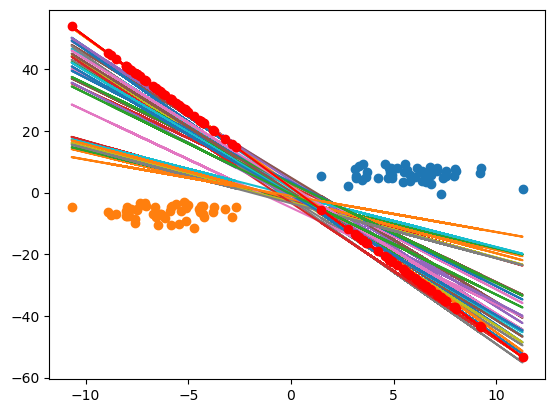
现在我们就可以看到那个最优的直线了,就是众多红色的点连接起来的那根线。
当然,最后代码执行顺序和讲解顺序有一些不一样,为了避免数据每次重新生成造成的差别,所以最开始是生成数据,之后是定义函数、过滤参数以及生成图像。
这个就是支持向量机的原理,我们找到离它所有的点的一个距离,让它这个边距最大,最后得到一个简化结果。
核函数
然后我们再来看另外一个点:「核函数」:
核函数是支持向量机里面非常重要的一个东西。
如果支持向量机只要数据是线性可分的,那么我们一定能够找到它的分割线。但是在实际的现实生活中有很多点并不是线性可分的。
举个例子,我们来画一张图:
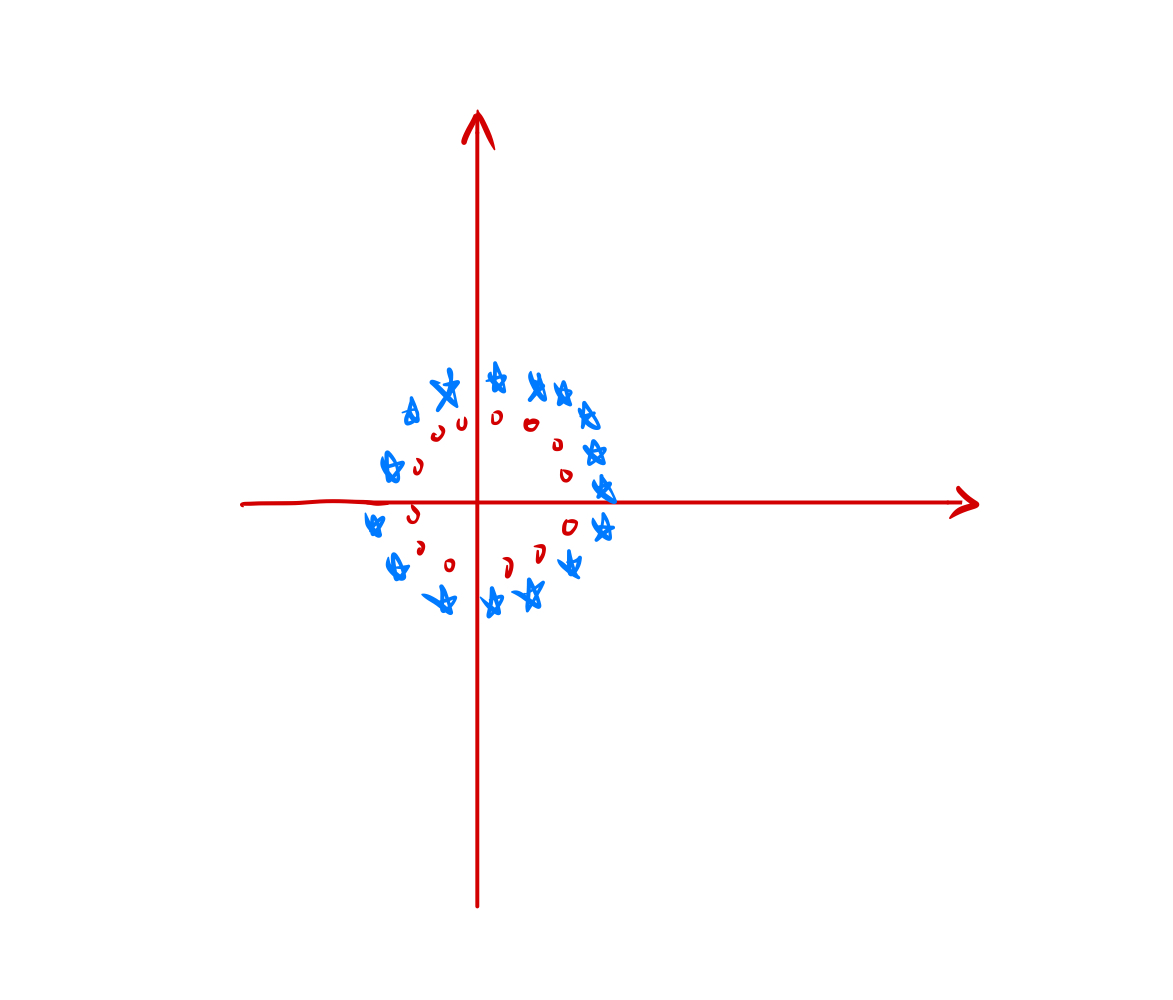
就比如图中的这种数据,是无论如何用一条直线无法分割的,不管怎么画,都无法把蓝色和红色的点分割开。
就像我们下面这张图:
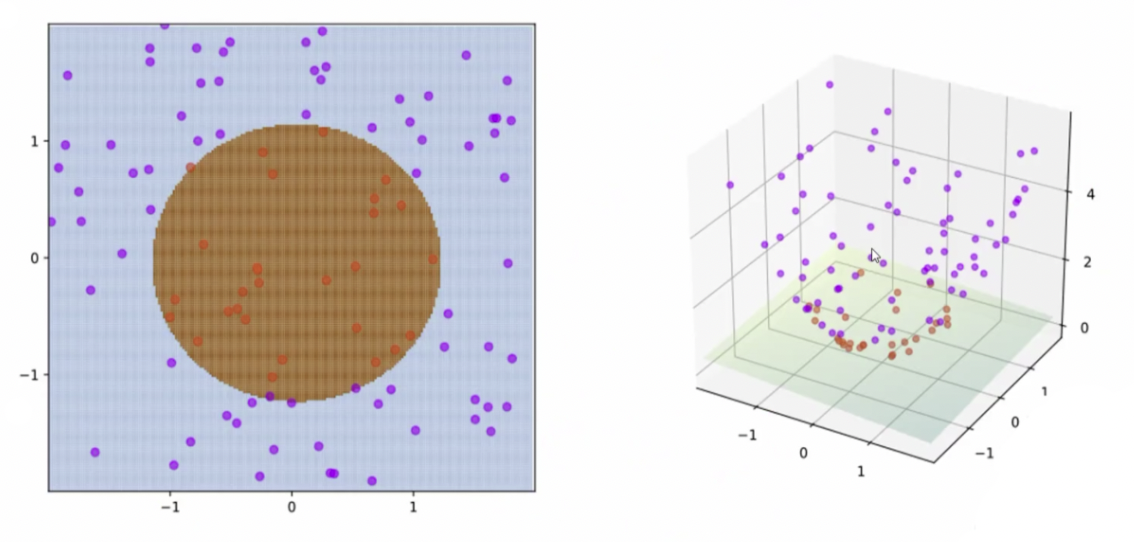
但是,我们我们可以做这样一件事情,假设我们在一个坐标轴上拥有 8 个点,A、B、C、D 为一组,a,b,c,d 为一组。如下图:
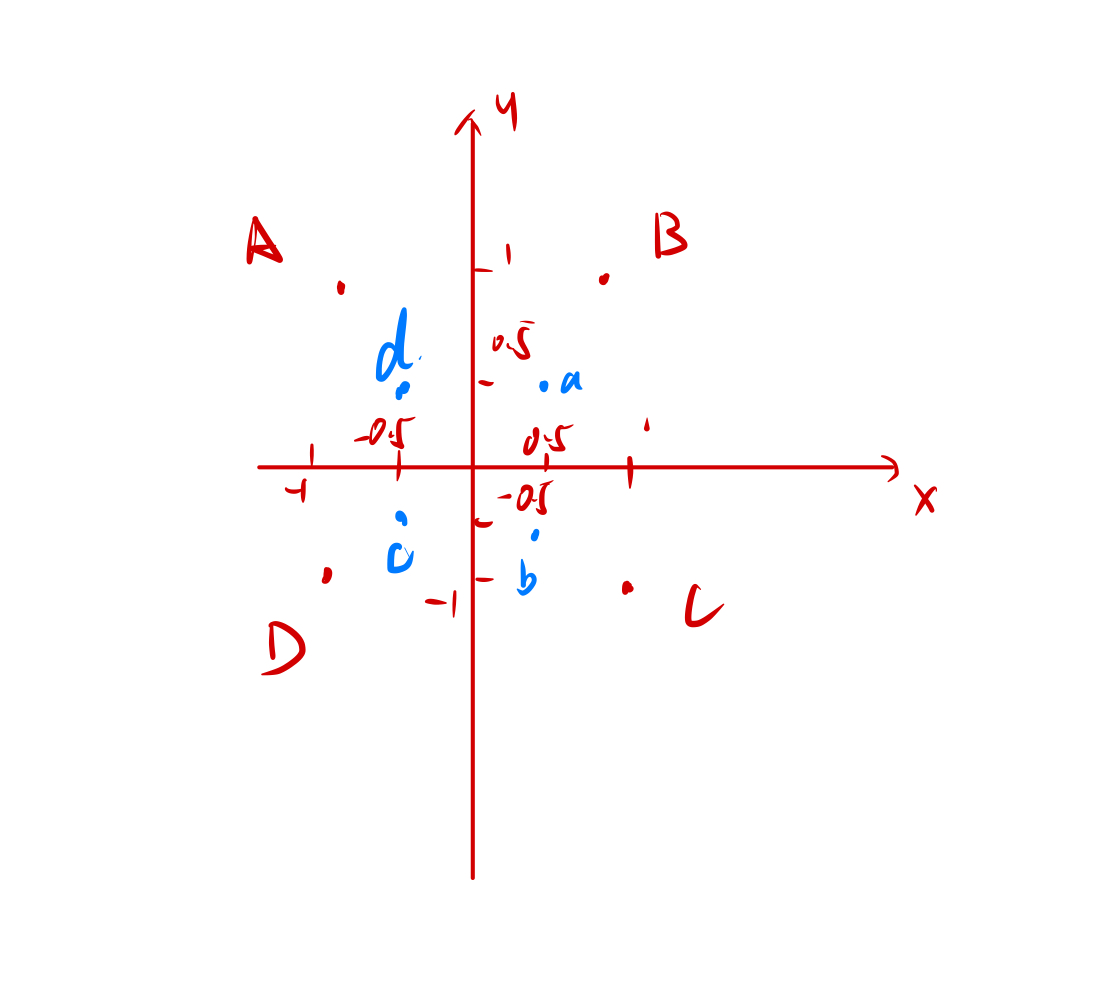
分别为 A(-1,1), B(1,1), C(1, -1), D(-1,-1);a(-0.5, 0.5), b(0.5, 0.5), c(0.5, -0.5), d(-0.5, -0.5)。
现在我们 ABCD 和 abcd 是无法用一根直线来分割的,然后我们令:
\[ \begin{align*} f(x) => \begin{Bmatrix} x^2 \\ y^2 \end{Bmatrix} \end{align*} \]
那在这种情况下,八个点分别就变成了 A(1, 1),B(1, 1),C(1, 1),D(1, 1),a(0.25, 0.25),b(0.25, 0.25),c(0.25, 0.25),d(0.25, 0.25)。
那这样的情况下,我们就完全可以用一根直线去分割了:
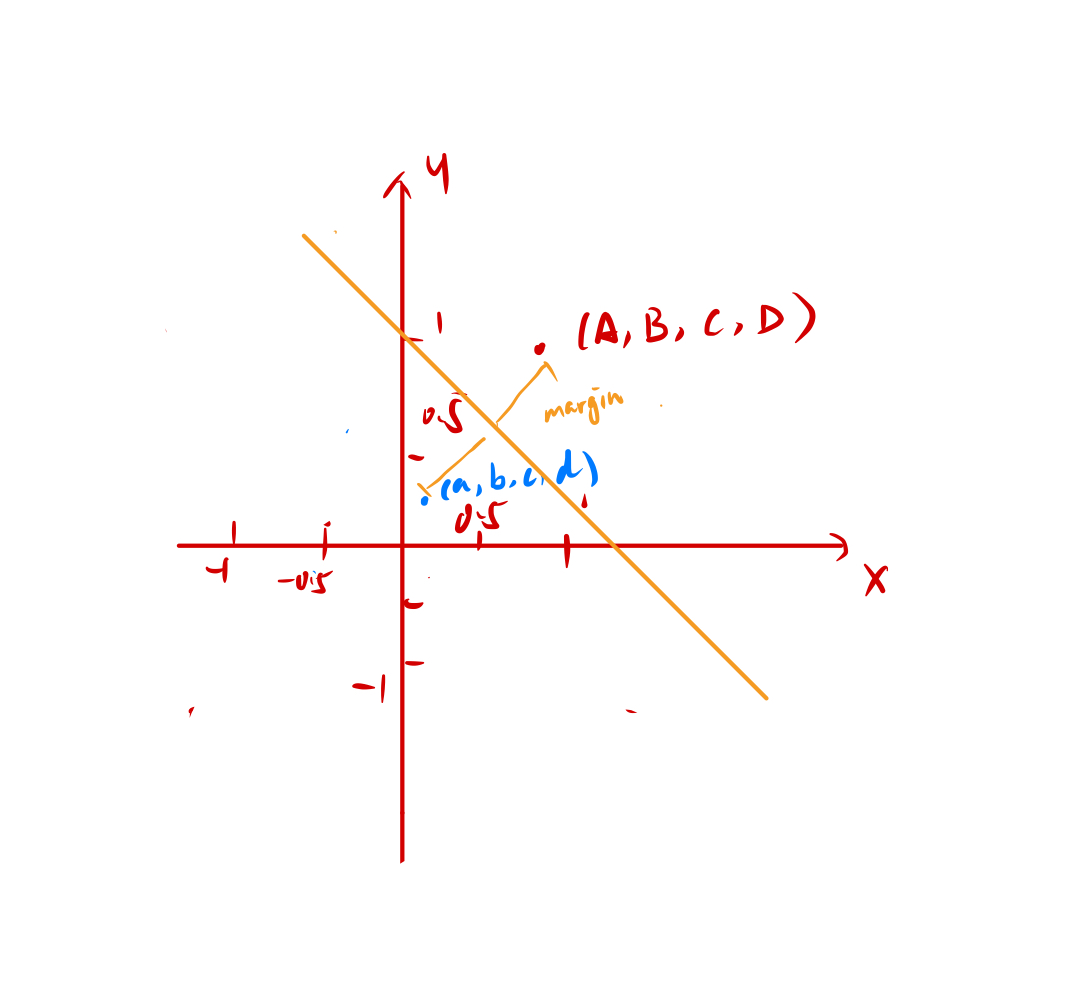
那现在找到这根线是 w2 = wx+b,那我们遇到新数据应用到这个函数里边,再应用到这个线里面做分割就可以了。我们把原本线性不可分的东西,变成线性可分的。那么这个就是核函数神奇的地方。
支持向量机通过某非线性变换 φ(x) ,将输入空间映射到高维特征空间。特征空间的维数可能非常高。如果支持向量机的求解只用到内积运算,而在低维输入空间又存在某个函数 K(x, x′) ,它恰好等于在高维空间中这个内积,即 K(x, x′) =φ(x)⋅φ(x') ; 。那么支持向量机就不用计算复杂的非线性变换,而由这个函数 K(x, x′) 直接得到非线性变换的内积,使大大简化了计算。我们就将这种函数函数 K(x, x′) 称为核函数。
\[ \varphi (x) = \begin{bmatrix} x \\ x^2 \\ x^3 \end{bmatrix} \]
那其实,就类似的事情,已经有人总结了一些相应的公式来使用:
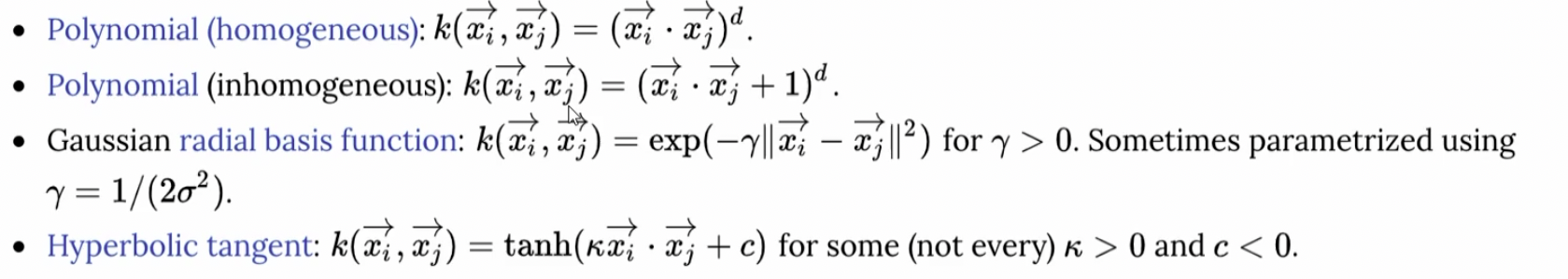
这些是一些常见的核函数。
一般在使用的时候调用它就可以,如果在用 SVM 的时候,它会有一个参数。可以自己定义一个核函数,但一般不自己定义,调用现有的就够了。
SVM 其实也有弊端,当数据量很复杂的时候,现有的核函数就没有作用了。因为它会失效,所以我们需要很多的人工分析,整个效率很低。
但是在整个机器学习的发展史上,它曾经有非常重要的一段历史。有一段时间它的论文量非常的多,做科研的非常爱做 SVM,不是因为快速,是因为可以提出来各种各样的 Kerno 函数。
假如有一组数据不好分割,但是你提出了一种新的核函数,这个函数量可以比较复杂啊 然后提升了分割率,提高了效果。
但是这种方法其实曾经一度让机器学习非常不受人待见,在学术圈非常不受人待见。搞机器学习的人就是每天就是发论文,说我的曲线比你的曲线强,这就是他们干的事。
所以 10 年左右,做机器学习、做人工智能的人都不说自己是做机器学习,做人工智能的。都换个名字,说做文本挖掘等等。
SVM 因为要做各种升维,当数据量比较大的时候,计算量非常的复杂,计算需求量非常的大。
但是 SVM 它有个好处,就是它比较直观,还有就是 SVM 对于不平衡的数据比较有用。
好,这节课我们就讲到这里,下一节课我们来看「决策树」。
关注「坍缩的奇点」,第一时间获取更多免费 AI 教程。

15. 机器学习 - 支持向量机

