18. BI - SlopeOne 原始算法、优化算法的原理及应用
本文为 「茶桁的 AI 秘籍 - BI 篇 第 18 篇」

[TOC]
Hi,你好。我是茶桁。
上节课的内容中,我们介绍了 Surprise 工具箱以及其中的 BaselineOnly,最后我们简单实现了一下。这一节课中,咱们来看看 Surprise 中的另外一个内容,SlopeOne 算法。
Slope One 算法
SlopeOne 算法是在 2005 年提出的一个 item-based 的协同过滤推荐算法,提出人是 Daniel lemire。
这个算法最大的有点在于算法很简单,易于实现,效率高且推荐准确度较高。
咱们来看一下这个表格:
| 用户 | 商品 1 评分 | 商品 2 |
|---|---|---|
| A | 5 | 3 |
| B | 4 | 3 |
| C | 4 | ? |
有 3 个用户对商品做了打分,用户 A 打了 5 分和 3 分给商品 1 和商品 2,B 给商品 1 打了 4 分,给商品 2 打了 3 分,C 给商品 1 打了 4 分,那请问 C 会给商品 2 打几分?
这是个协同过滤,所以我们会利用已有的一些用户对商品的评分。你们觉得 C 会给商品 2 打几分?这个分数的打法怎么打,我们的打法是要找过滤,找到 1 和 2 之间的一些差别。
可以打 3 分,为什么?因为 C 和 B 很像,B 打三分,所以认为 C 也应该是 3 分。这其实类似于邻近方法,它不是 SlopeOne,这也是一种策略。
那 SlopeOne 的策略是什么?它会这么认为:你看 1 是不是比 2 要好?好多少,我们要把规律学出来。
这里有两个样本,5 - 3 是第一个人,第二个人是 4 - 3。一共有两个人所以除上 2:C 对商品 2 的评分 = 4 - ((5-3)+(4-3))/2 = 2.5。
其实就是 1 比 2 要好 1.5 分,平均分要好 1.5 分。那么对于 C 来说的第 1 个商品评分是 4, 4 - 1.5 就变成了 2.5。这个就是 SlopeOne 的一个原理。
SlopeOne 就是先去找一个规律,然后去应用规律,把空的给它填上。
我们来总结一下 SlopeOne 算法: - Step1, 计算 Item 之间的评分差的均值,记为评分偏差(两个 item 都评分过的用户)
\[ \begin{align*} & 商品 i 和 j 之间被共同用户打分过的个数。\\ & dev_{j,i} = \sum_{u\in S_{j,i}(x)}\frac{u_j-u_i}{card(S_{j,i}(x))} \end{align*} \]
首先,商品和商品之间应该是有一些规律的偏差的,我们把这个均值求出来,这是第一个找规律的阶段。 - Step2, 根据 Item 间的评分偏差和用户的历史评分,预测用户对未评分的 item 的评分
\[ \begin{align*} P(u)_j & = \frac{1}{card(R_j)}(dev_{j,i} + u_i) \\ P^{S1}(u)_j & = \overline u + \frac{1}{card(R_j)}\sum_{i\in R_j} dev_{j, i} \end{align*} \]
第二阶段是利用刚才找到的这个规律和用户的评分来去预测用户没有评分的商品。第二阶段叫做用规律,用完规律预测出来的分值去做排序,排序以后的结果推荐给用户。 - Step3, 将预测评分排序,取 topN 对应的 item 推荐给用户。
看看 SlopeOne 的原理,感觉起来应该也还好。我们来一个比原来稍微复杂一点点的一个例子一起来看一下。
| a | b | c | d | |
|---|---|---|---|---|
| A | 5 | 3.5 | ? | ? |
| B | 2 | 5 | 4 | 2 |
| C | 4.5 | 3.5 | 1 | 4 |
三个用户 A, B,C,四个商品 a、b、c,d。用户 A 对它的打分,B 的打分,C 的打分。现在就是要预测用户 A 对 c 和 d 的打分是多少。
我们用 SlopeOne,刚才咱们说的第一步就是要去找商品的规律,我们先看 b 和 a 之间的规律,b 和 a 之间的规律的是三个用户都打分了,因此是
\[ \begin{align*} b \ and \ a: ((3.5-5)+(5-2)+(3.5-4.5))/3 = 0.5/3 = 1/6 \end{align*} \]
计算的结果,b 比 a 要好 1/6。
这个规律学完以后再去看 c 和 a 的规律,c 和 a 出现过几个样本?应该是 2 个,用户 B 和用户 C:
\[ \begin{align*} c \ and \ a: ((4-2)+(1-4.5))/2 = -1.5/2 = -\frac{3}{4} \end{align*} \]
也就是\(-\frac{3}{4}\)。
接着依次来找剩余的规律,包含上面的两个,完整的规律就应该是
\[ \begin{align*} b \ and \ a: & ((3.5-5)+(5-2)+(3.5-4.5))/3 = 0.5/3 = 0.17 \\ c \ and \ a: & ((4-2)+(1-4.5))/2 = -1.5/2 = -0.75 \\ d \ and \ a: & ((2-2)+(4-4.5))/2 = -0.5/2 = -0.25 \\ c \ and \ b: & ((4-5)+(1-3.5))/2 = -3.5/2 = -1.75 \\ d \ and \ b: & ((2-5)+(4-3.5))/2 = -2.5/2 = -1.25 \\ d \ and \ c: & ((2-4)+(4-1))/2 = 1/2 = 0.5 \end{align*} \]
这个过程就是计算两两之间的一个均值的偏差,叫找规律。把两个均值间的差值计算了出来。
上面这个过程找好规律就要用规律了,要预测用户 A 对于商品 c 和 d 的评分,那么用户 A 对商品 c 的评分怎么去运用它的一个规律呢?
| a | b | c | d | |
|---|---|---|---|---|
| a | ||||
| b | 0.17 | |||
| c | -0.75 | -1.75 | ||
| d | -0.25 | -1.25 | 0.5 |
来看这个之前找规律时计算的结果,c 是有 2 个, c 和 a 之间是 -0.75, c 和 b 之间是-1.75, 再看 d,有三个,d 和 a 之间是-0.25, d 和 b 之间是-1.25, d 和 c 之间是 0.5。
那 A 对 c 和 d 的评分就应该是:
\[ \begin{align*} A 对 c 的评分 & = ((-0.75+5)+(-1.75+3.5))/2 = 3 \\ A 对 d 的评分 & = ((-0.25+5)+(-1.25 + 3.5))/2 = 3.5 \end{align*} \]
有了这个结果之后,就可以将 c 和 d 进行排序,排序结果是 d
的预测评分大于 c,那 A 可能更偏好于 d,我们就给用户 A 推荐 d
商品。预测评分排序结果就为 {d, c}。
以上就是一个原理,先去找两点之间的规律,再把这个规律应用于未知的地方,再去求每个未知。过程中我们都是找这个未知跟已知之间的原有规律的计算,把它推演出来。
最好的方式还是代入进去自己去推算一下,最开始的那个过程应该都比较好理解,比较简单。后面就稍微复杂一点,但实际上再怎么复杂两两之间规律都肯定能计算出来。
ALS 和 SlopeOne 这两种方法都是协同过滤,都是猜你喜欢,猜矩阵的值。SlopeOne 它没有学内容,它就直接计算。SlopeOne 这个方法其实原理也比较清晰,就是找两两之间的规律,通过这些数据来做个判断,然后再去应用就好。
它虽然是协同过滤,但是实际上没有太多学习的过程,它的学习也就是把以前的那个差值给他计算出来,统计的方式。
ALS 最大的使用特点就是把矩阵降维处理了,把稀疏变成稠密再进行预测。
SlopeOne 这个方法实际上在一篇论文里面可以找到。这篇论文的作者在论文里面提到了三种方法,刚才看到的是第一种 SlopeOne,其实还有一种在原有基础上做的改进叫 Weighted SlopeOne,其实就是加权的方式。
如果有 100 个用户对 Item1 和 Item2 都打过分,有 1000 个用户对 Item3 和 Item2 也打过分,显然这两个 rating 差的权重是不一样的,因此计算方法为:
\[ \begin{align*} (100 \cdot (Rating 1 to 2) + 1000 \cdot (Rating 3 to 2)) / (100 + 1000) \end{align*} \]
有 100 个用户对商品 1 和商品 2 都打过分, 还有 2 和 3 之间的规律是有 1,000 个人的打分。那么这两个矩阵的打分权重一样吗?以往的方式,最原始的 SlopeOne 的方式是一样的,而现在认为是有些差别的。1 和 2 的权重是 100,2 和 3 的权重变成了 1,000。最后我们除上它,整个的平均就是 1,100。
加 Weighted 实际上是一个比较容易的一种加权方式,这种加权的方法就考虑了不同的权重的概念。
SlopeOne 的特点是作商品和商品之间的规律,对于商品不太更新的内容它就会比较稳定,也就是适用于 item 更新不频繁,数量相对较稳定的。相反,如果商品天天更新是不太好用。
item 数要小于 user 数。因为商品和商品之间是两两之间都要计算规律的,item 数量如果很大我们的计算规律的数量也会很多,算法的效率也是个问题,所以它适合于 item 不太更新的场景,item 要小于 user 数。
整体来说算法比较简单,易于实现,执行效率比较高。
但是它是依赖于用户行为,存在冷启动问题和稀疏性问题。也就是用户需要对商品来做打分。
其实,只要是协同过滤的话都存在冷启动问题。比如说用户对商品,如果是个新的用户,没有商品打分,你就没法利用他以前的规律来进行操作。
稀疏性问题 ALS 相对来说会好一点。它毕竟还有个降维处理,可以帮你来变得更加稠密一些。
实现起来其实和之前也没有太大的区别,就是调用的包会不一样。
1 | |
我们还是预估 196 对 302 这个商品,那结果也还可以,原始值是 4, 预测出来的结果是 4.32。
Surprise 推荐系统工具
SlopeOne 是在 surprise 里的一个工具,surprise 是一个工具箱,里面还有非常多的一些其他的工具。比如说基于邻域的协同过滤,你的邻域可以用 KNN 找邻居的方法: KNNBaseline,这里就不讲原理了,KNN 原理前面的课程讲过很多,只让大家体验一下什么是邻域,什么是基于内存。
1 | |
我们运行一下看看内存:

在运行之前,还只用了 5 个 G 内存,运行之后直接飙到了 13.89G,如果这个 Python 已经运行完了就会瞬间下降,降到原来的的 5 个 G。这就是为什么叫做基于内存的过滤。
好,总结一下。这几节课我们矩阵分解内容就基本讲完了,首先矩阵分解是个隐语义的概念,隐语义通过隐分类去匹配用户和商品之间来做推荐,他把原来的平行矩阵 R 做了一个降维的处理,分成了两个小矩阵:User 矩阵和 Item 矩阵,User 每一行代表一个用户的向量,Item 每一列代表一个 item 的向量。将 User 和 Item 的维度降低到隐类别个数的维度。
根据用户行为,矩阵分解可以分为显式矩阵分解和隐式矩阵分解。显式 MF 中,用户向量和物品向量的内积拟合的是用户对物品的实际评分,隐式 MF 中,用户向量和物品向量的内积拟合的是用户对物品的偏好(0 或 1),拟合的强度由置信度控制,置信度又由行为的强度决定。
ALS&SGD
ALS 和 SGD 都是数学上的优化方法,这两种方法也都给大家说了一下,可以解决最优化问题(损失函数最小化)。
ALS-WR 算法,可以解决过拟合问题,当隐特征个数很多的时候也不会造成过拟合。ALS,SGD 都可以进行并行化处理,SGD 方法可以不需要遍历所有的样本即可完成特征向量的求解。
Facebook 把这两种方法都进行了揉合提出来一种新的策略,旋转混合式求解方法,可以处理 1,000 亿的数据。这数量级非常庞大,而且效率还比 Spark mllib 快了有 10 倍。
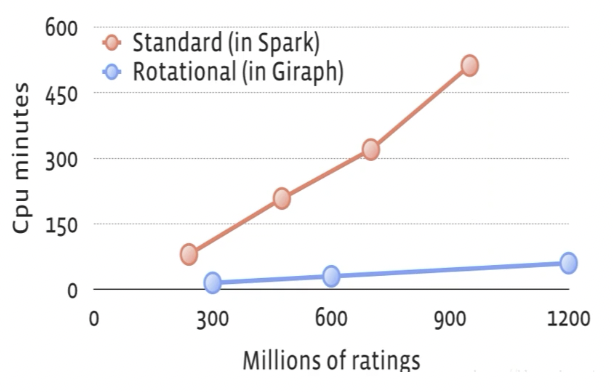
从张图计算时间的图来看,Spark 是红色,Giraph 是蓝色,就 Facebook 提出来这个方法,它的计算时间是原来的 1/10。所以把这两种方法融合到一起提供一种螺旋式的求解方式,这样求解的效率,得出来参数的拟合速度会更快一点。
具体使用的时候当然就是调包,我们有 Surprise 这个工具箱,里面有很多的方法。之前给大家讲过,它是 Scikit 家族的,使用起来和 sklearn 也很像。它内置了 ALS 和 SGD 等多种优化算法,还有一些预测算法,包括基线算法,邻域方法,矩阵分解,SlopeOne 等等,这些也在之前的课程中给大家都讲解过。除了这些之外,还有一些没有讲的内容,比如相似性度量,内置 cosine,MSD,pearson 等等。
这个就是咱们今天这节课的主要内容了,那下一节课中,咱们来看一个论文。虽然是比较早的一篇论文了,但是阅读论文也是一种能力,如果你想要未来获取大量的一些新的方法,读取论文是最直接的方式。
18. BI - SlopeOne 原始算法、优化算法的原理及应用

