24. BI - 一篇文章带你详细理解特征工程核心:Embedding
本文为 「茶桁的 AI 秘籍 - BI 篇 第 24 篇」

[TOC]
Hi,你好。我是茶桁。
上一节课上,咱们学习了基于内容做推荐的一些内容,就着一个酒店的案例,将整个基于内容做推荐的流程跑了一遍,在其中我们还讲解了 N-Gram 方法,这其实算是咱们一个 NLP 的方法。
推荐系统和 NLP 结合场景多吗?其实还是挺多的。推荐系统分几个引擎,内容推荐一般是文本内容,这个跟 NLP 结合的非常多。这是在内容推荐的基础上主要做相似度推荐。所以推荐系统它是一个综合性的应用场景。
现在直播很火对吧?抖音直播,淘宝直播,京东直播,还有各种大大小小的直播平台。那直播里可能经常会上一个货架,不知道大家有没有去遇到主播进行直播的时候把连接上错的情况。好像以前老罗还是谁就干过这种事。
那直播带货没有没有上错连接呢?有这种可能性的,如果上错损失还是非常严重的,我以前就见到过一个。
那直播里可以有一个算法来帮你去做标签的匹配,就是帮你做链接匹配。
怎么做?主播在去穿某一个衣服或者擦某一个口红,你都可以去通过图像的方式来做识别,识别以后去做一个链接的一个匹配。所以推荐系统里面其实也可以对图像来去做一些结合,也就是咱们的 CV 部分。
除了直播之外,跟图像相关可以做推荐的还有什么?那大家逛淘宝的时候有一个拍照识别的场景,不知道大家有没有人用过。你并不知道商品名称,也不知道商品到底是在哪里可以找到,只有一张这个商品的图片,上面包含了一些基本特征。这个时候我们就可以把这张照片上传上去,让淘宝给你推荐跟他类似的商品,也很有可能是完全一致。如果不是,某些特征尽量一致也 OK。所以淘宝上也有一个是拍照识别推荐。
所以回到推荐系统,它是一个综合性的应用场景。文字有需求,图片也有需求,用户行为也有需求。所以不同的场景可能需要不同的引擎,内容算是一个比较常见的一个引擎。因为你上架商品总会写一些文字的,那这样的一个文字描述和一些录入的特征提取出来,咱们描述里可以提取 TF-IDF 这样的特征,就可以做相似度计算。这个就是上节课讲到的内容推荐系统的一个概念了。
那内容推荐系统只用 TF-IDF
会不会不太准,可能缺失的内容会比较多呢?那我们还会有另一个方法,叫做word Embedding。
Word Embedding
应该会有人见过Embedding这个单词吧?在网上出现的频次还蛮高的,包括一些推荐系统的论文,这个单词出现的频次也非常大。现在我们看到
embedding 已经不仅仅是在单词的特征表达了,还有一些图的
embedding,还有很多的 item 的
embedding。你只要把它看成一个物体,可以用向量来做表达就可以把它称为叫做
embedding 的一个策略,应用场景非常的广泛。
第二个场景就是在深度学习。现在推荐系统已经进入到深度学习的阶段,尤其是在互联网公司里面。那么深度学习 embedding 就是个标配。怎么理解标配?标配就是他一定会做的一个配置。
所以我们先看一看 Embedding 的概念。Embedding 中文就是「嵌入」。它是一种降维方式,将不同特征转换为维度相同的向量,他嵌入是要嵌入到固定大小的一个向量盒子里面去。
原来如果不做 Embedding 那你可能会做一些特征编码,比如说以 one-hot 为例,咱们机器学习基础课程里有详细讲过 One-Hot,它会带来怎样一个后果呢?你做了 one-hot,每一个都会成为一个独立的一例,就是你出现多少个值就会有多少个特征例,它的维度就非常非常的庞大,这么大的一些维度在后续运算过程中会造成很大的一个计算量。所以为了方便我们还需要给它做一个嵌入。
现在 Embedding 是个技术,可以把它理解成是个降维技术,或者叫嵌入技术。任何物体,都可以将它转换成为向量的形式,从 Trait #1 到#N。我们以人来举例,把人去做一个 embedding,用一个向量的方式来做表达。那向量之间,就可以使用相似度进行计算。
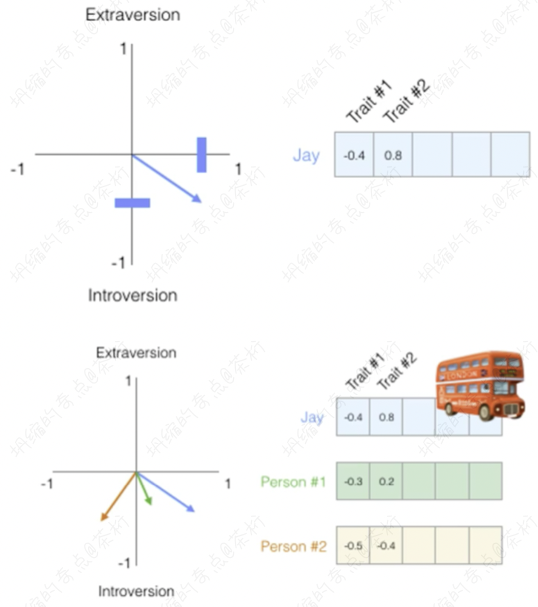
Jay,这是一个人。它有两个维度,负的 0.4 和 0.8。解读一下,比如说第一个维度,负的 0.4 可能代表性格,性格可能不是很好。然后后面这个 0.8 代表有钱,那 Jay 是性格不太好,但是比较有钱。
大于 0 就代表是正向的、比较好的,小于 0 是在这个维度上是反向的。除了 Jay 以外,还有 person1 和 person2。那么我们来看一下,觉得 Jay 这个人跟哪一个 person 的相似度是最大的?
每一个人都有向量的表达,用向量在平面作坐标系上来进行绘制,蓝色的箭头跟绿色和粉色哪一个更接近呢?就是和 Person1 更接近。为什么?因为它夹角小。不过具体是怎么算的?我们现在用的方式也是用余弦的方法,套用一下上节课咱们用的方法:

我们采用cosine_similarities,把这两个值求余弦就得出来了。跟
Person1 是0.87,和 Person2
是等于-0.20。那你看谁会更好?非常明显应该是 Person1。
前面这个向量计算大家应该能明白,我们只是说 embedding 的使用是怎么用的。embedding 就是一个向量维度,它的使用就是做余弦用的,帮你来去分析谁会更接近,然后从大到小来去做一个相关的推荐。
将 word 进行 embedding
可以表达很多的维度,咱们以一个单词为例,king这个单词。这个单词在网上已经有别人训练好了,并且把训练好的这个数字给你展示出来。

咱们来数一数,大概 king 这个单词可能有 50 个维度,每个维度现在都有一些相关的一些数值,数值越大代表它特征越明显。如果你维度非常多,看数字不如直接看颜色,色块。

为了方便去解读这个数值,咱们来做了一个热力图的图例。那这个就是king的热力图。
咱们还有一些其他的英文单词,比如说Man,
Woamn:

从上面这个例子来去看,man和woman还是比较接近的,man
和 king 也还是比较接近。
这些单词的向量表达,我们得到以后目标是啥?embedding 不等于我们的目标,embedding 是中间状态,这个状态就是你的特征的表达。
咱们已经把 king,man 和 woman
都做成特征的表达,它的目标是要计算。所以 Embedding
有两个价值,第一个叫固定维度,让原来 one-hot
编码产生特征爆炸的,或者维度不固定的把它固定下来。固定维度以后为了后续的可计算可以做各种各样的一些计算。有哪些计算任务呢?第一个常见的方式就是比较最接近的单词有哪些。第二个还可以做一些加加减减,我们来看一下king-man+woman:
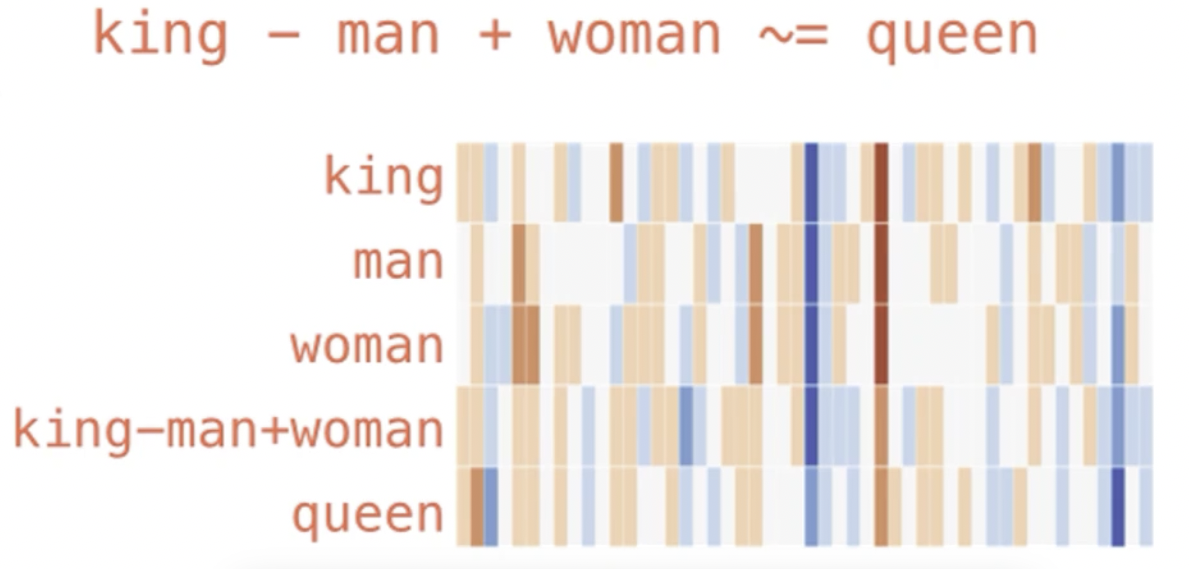
可以看到,这样一计算之后,与 queen 的相似度还是蛮高的。最后我们计算得到的值约等于 queen。国王减去男人,剩下的部分再加上女人就等于 queen。
1 | |
我们在调包的过程中也很明显能看出来 queen 是排到第一的。比如说 king
加上 woman,positive是正向的,negative就是减去
man,就等于这些个值。这个值里面从大到小做排序,queen 是 0.85
排到第一,其次是throne,应该是皇冠,后面还有prince等等。
所以 Embedding 就是固定了向量维度以后,方便你后续的计算。计算可以去取它相对最高的那一个作为后续的一个推荐的过程。
那怎么样变成 embedding 呢?我们就要用到 Google
的一个工具:Word2Vec,Word2Vec
是把一些单词映射到新的空间中。
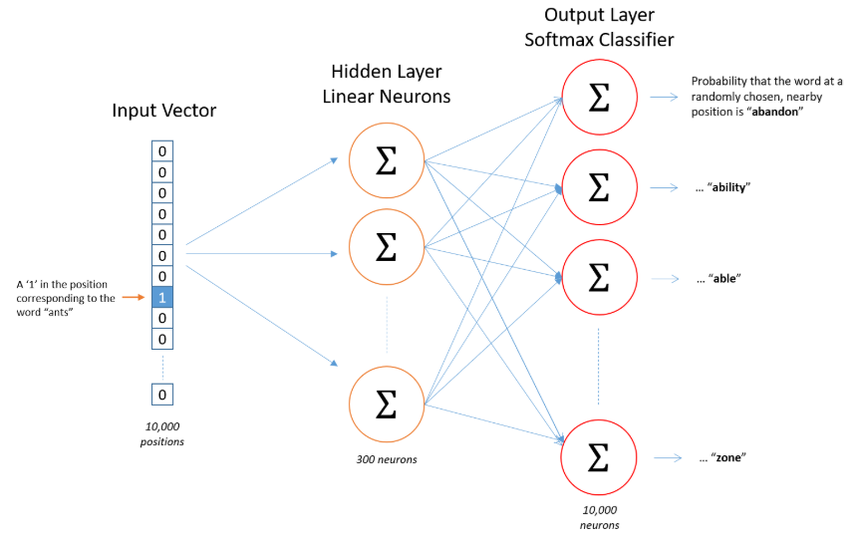
来看一张图,这张图是一个神经网络,神经网络有很多神经元组成。中间有 300 个神经元,最开始这个 input 输入的是什么?是你的某一个单词。想要去学习这些单词,预测它的上下文更有可能是哪些单词,Word2Vec 做了一个假想的任务,去预测它上下文的单词能不能预测准。这个就是 Word2Vec 的一个想法。
通过 Embedding,把原先词所在空间映射到一个新的空间中去,使得语义上相似的单词在该空间内距离相近。
Embedding 层是在哪一层?是在 input 层还是在隐藏层,还是在输出层?
原始数据 data 是带在 input 层,原始数据现在用的 one-hot
编码,这个编码不等于 embedding。以ants为例,one-hot 是 0,1
编码,如果有的话就为 1,没有就为 0。那说明输入层上标 1
的这一位就是ants的一个表征的方式。
然后我们就需要给它展开到 300 维的神经元,实际上对于 ants 的表达我们想要去拟合这个特征的定义,然后把这个特征用于后续的预测任务,预测它的上下文,一共有 1 万个神经元。
Word Embedding 是在学习隐藏层的权重矩阵。输入层不是 embedding,就是输入层,因为它是个原始数据。这个原始数据是由 one-hot 编码,就是 0,1 编码。
隐藏层的神经元数量为 hidden_size(Embedding
Size)。对于输入层和隐藏层之间的权值矩阵
W,大小为[vocab_size, hidden_size]。输出层为[vocab_size]大小的向量,每一个值代表着输出一个词的频率。
那为什么 Embedding 是在中间层?
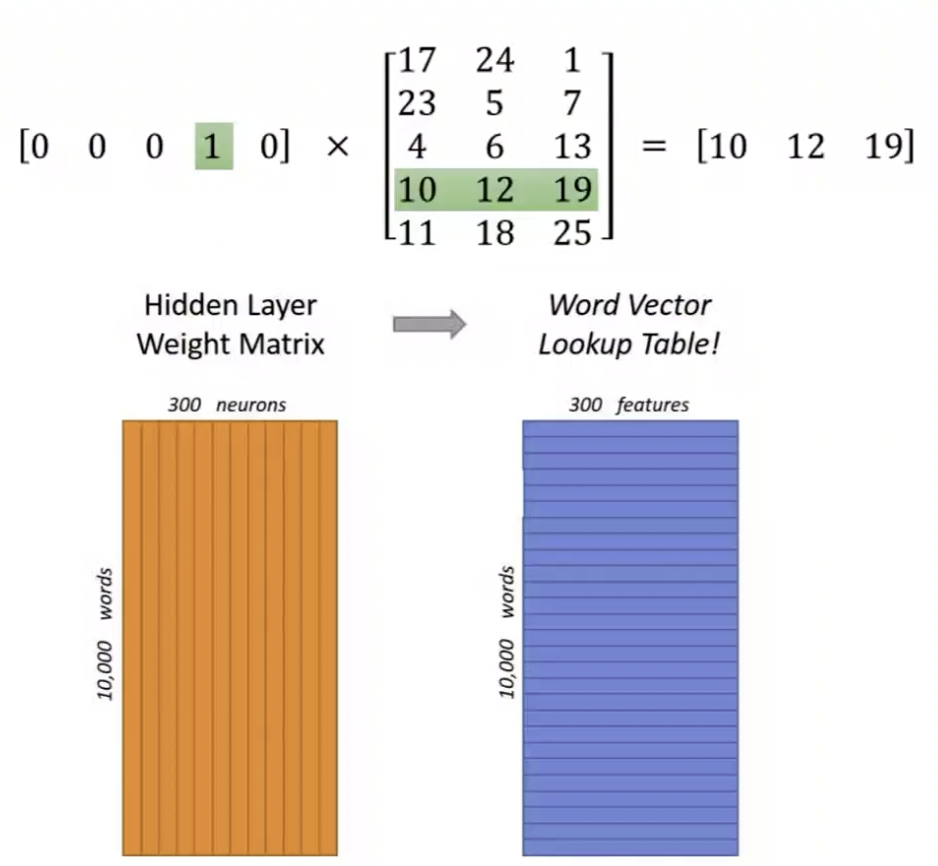
one-hot 编码里面存在部分 1 了,中间的矩阵部分是个神经元。这个神经元可以理解成为是一个叫单词向量的 look up table,查找表。有的为 1 就相当于把这个行给它激活了,激活以后相当于就是求了一个 embedding 的 look up,在表格中做了一个查询,检索出来是 10、12、19,三个单词的特征,维度就求出来了。
求完以后目的是什么?就是要预测它的上下文,它的上下文可能是什么。这是 Word2Vec 的一个使用方法。
我们来看上面那张图,左边黄色的部分是一个大的矩阵,这个矩阵是
Embedding 的 look up,现在选择了ants=1,
把其中一行进行激活,激活以后这个特征就可以完成后续的一些任务了。
神经网络呢是原始数据输入以后,中间要做一个特征的抽取。神经网络之所以神奇,是因为它可以做自动的特征抽取。我们抽取出来,只需要固定出来想要抽多少特征就好了。这 300 维它可以自动来进行拟合,目标就是要预测更准。
所以神经网络是要有学习机制的,你要让它运行多次,让你的参数进行拟合,让你的 loss 损失函数更小。拟合好之后就是在中间层,也就是 300 层的那个 Hidden layer 帮你做后续的任务。
那训练怎么去拟合这个参数?我们需要有一个训练任务,Word2Vec 有两种任务模式,一种叫做 skip-Gram,还有一种叫做 CBOW。
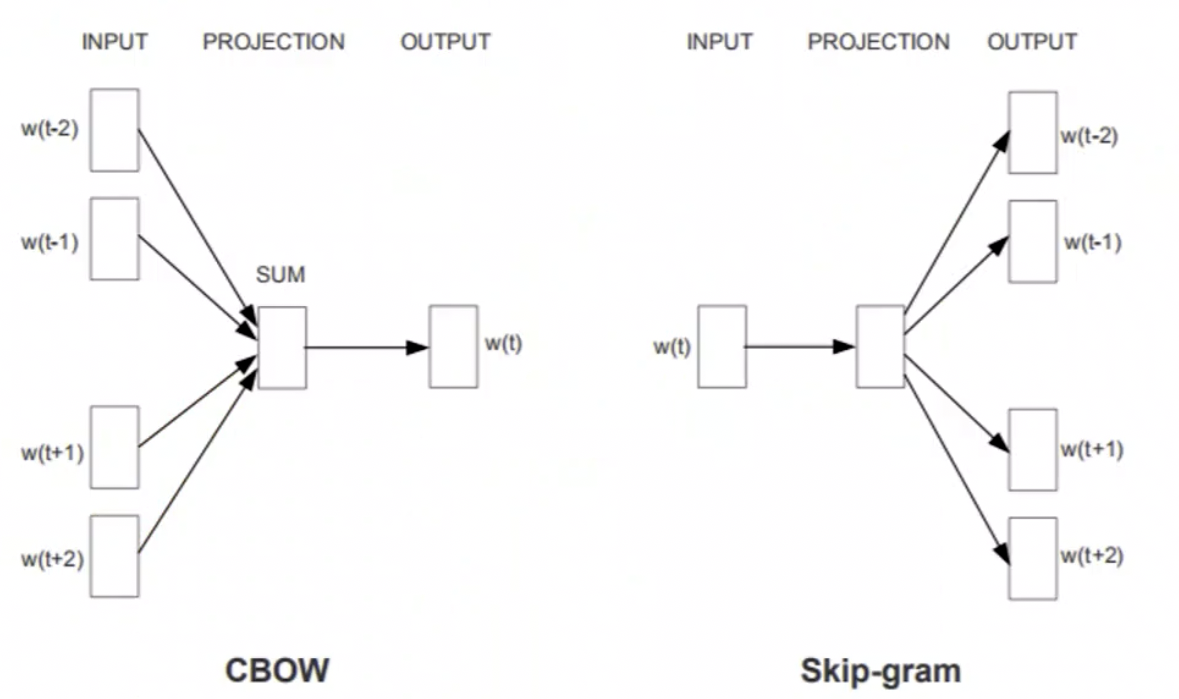
我们来看看右侧的 Skip-Gram。得到的一个中间的一个 Embedding,想让它去预测两边。就是给定 input word 预测上下文。
那左侧的 CBOW 和 Skip-Gram 则相反,是给你两边预测中间。也就是给定上下文,预测 input word。

这两种方式其实都是 OK 的,采用哪种方法都可以,都是去预测上下文。一个是两边预测中间,一个是中间预测两边。
那为什么采用这种方式来进行预测?我们要选其中的一个单词看它周围的单词可能是什么,得出来的一个数值还是能反映一些问题的,比如说国王和男人之间比较接近,男人和女人之间也有很多的相通之处。
举个例子,比如「我喜欢吃苹果」,英文是I love eating apple,苹果是一个农产品,是个水果。那你对它的表达是不是跟其他的水果之间应该比较接近?因为它会以前学习过很多一些语料,这个语料会发现除了
apple
可以这么说,还可以说别的英文,比如I love eating Banana\Orange。
所以这些水果它出现的先后的顺序、位置如果越接近,那它的 Embedding 就会越接近。Embedding 越接近,在进行检索的时候就很容易把这些相似的一些特点给检测出来。
所以 embedding 是一个词的特征向量,它要放到任务里面来进行学习才能收敛,让它效果针对于后续的任务才能更好。
Word2Vec
那到具体的使用上,我们可以安装 Gensim 工具箱:
1 | |
Gensim 是一个开源的 Python 工具包,可以从非结构化文本中,无监督地学习到 Hidden layer 的主题向量表达。Gensim 里面有非常多的一些主题模型,每一个向量变换的操作都对应着一个主题模型。今天使用的是 word2vec。
当然除了 word2vec, 它也支持 TF-IDF, LDA, LSA 等等多种主题模型算法。
在使用的第一步要去创建一个词向量模型:
1 | |
可以指定它的 size,这里的 size 代表 embedding size,就是你要压缩到的那个维度。然后针对这个模型可以做保存,因为你不需要下次再来做训练,只需要把模型保留下来以后直接 load 就可以。这样效率就会非常的快。
1 | |
word2vec 其实网上也有很多预训练模型,就是已经训练好的一些模型,这个模型可以直接用于我们的后续的预测。
我们直接来做一个例子,这个例子是使用了西游记这本书计算小说中的人物相似度,在做相似度计算的过程中我们可以看看每一个人名之间的相似度。西游记中是出现了很多的小说人物,有孙悟空、猪八戒、唐僧、孙行者等等。我们想来分析跟某一个人物相近的人物有哪些。
第一点,咱们这次是一个中文的环境,那是需要用到 jieba 这个分词工具把它分出来。分出来以后,就把它放到一个 sentence 的接待器,就是一个 sentence 的列表。然后再用 word2vec 这个工具来去做训练,最终得到两个单词的相似度。
好,那所使用到的文件是journey to the west的一个文本文件,这个文件也会随着我的源代码一起上传到项目仓库中。

那咱们首先要做的是要给它做一个切分,对其做分词之后将分好的内容输出到segment这个文件夹内。
那我们当然是要来写一个函数来做字词分割的任务
1 | |
然后咱们来保存 segment 文件
1 | |

这样基础工作就算是完成了,接下来咱们将刚才那个保存好的文件拿出来。
1 | |
拿到后,就可以进行模型设置和训练了, 之前咱们从已经切分好的文件夹里面把句子读出来, 现在要把句子喂给 word2vec,它背后的原理就会自动的去预测每个单词的上下文。
如果要你的上文预测的更准,中间特征工程很关键。所以你的 Word Embedding 就要拟合的很好才可以。
1 | |
直接model.wv就可以得到一个中间矩阵,然后基于它来计算孙悟空和猪八戒的强度,也计算一下孙悟空和孙行者强度。
计算完以后我们又写了一个方法,就是孙悟空+唐僧-孙行者等于什么,可以拿它一起来运行一下。
那首先第一个,孙悟空和猪八戒的相度是
0.931,已经很接近了,但是相比较而言,孙行者和孙悟空就更接近一点,是
0.949,不过也说的通,毕竟是一个人。
之后我们再去看一看咱们计算的结果,那针对这个计算后的结果它给了 10
个推荐结果,其中菩萨是最接近的,达到
0.958,长老次之,为
0.955。那这个结果貌似还是有一定的道理的。
除了咱们的vector_size等于
100,我们还可以调整其他的一些参数,比如说咱们将vector_size调整为
128, window调整为 5 再跑一次。
1 | |
重新计算的结果,孙悟空和猪八戒相似度是
0.925, 孙悟空和孙行者则是
0.939。它实际上是因为模型中的 vector size
发生了一些变化,所以计算同样的内容,结果有一些小的差别。要做对比是要比较它的相对值,哪一个更好,依然还是孙悟空和孙行者。
所以往往它的相对值不会发生一些变化,孙悟空和孙行者会更加的接近一些。
那这个例子也就给大家讲完了,word2vec 就直接调包,可以帮你去训练一个单词的词向量。这个词向量可以用于后续的内容推荐。比如我们用某一个文章,这个文章的词向量跟其他的之间越接近,就可以做相关内容推荐。包括我们现在人物也是一样的,去找它相关的一些内容。
那今天的课程咱们就讲完了,在最后我们再来说说对 Embedding 的理解。
Summary
Embedding 其实是一个广泛的概念,我们在之前的案例中使用了 SVD,其实也可以把它看成 embedding。
我们来看更早的那个例子中的一个矩阵图:
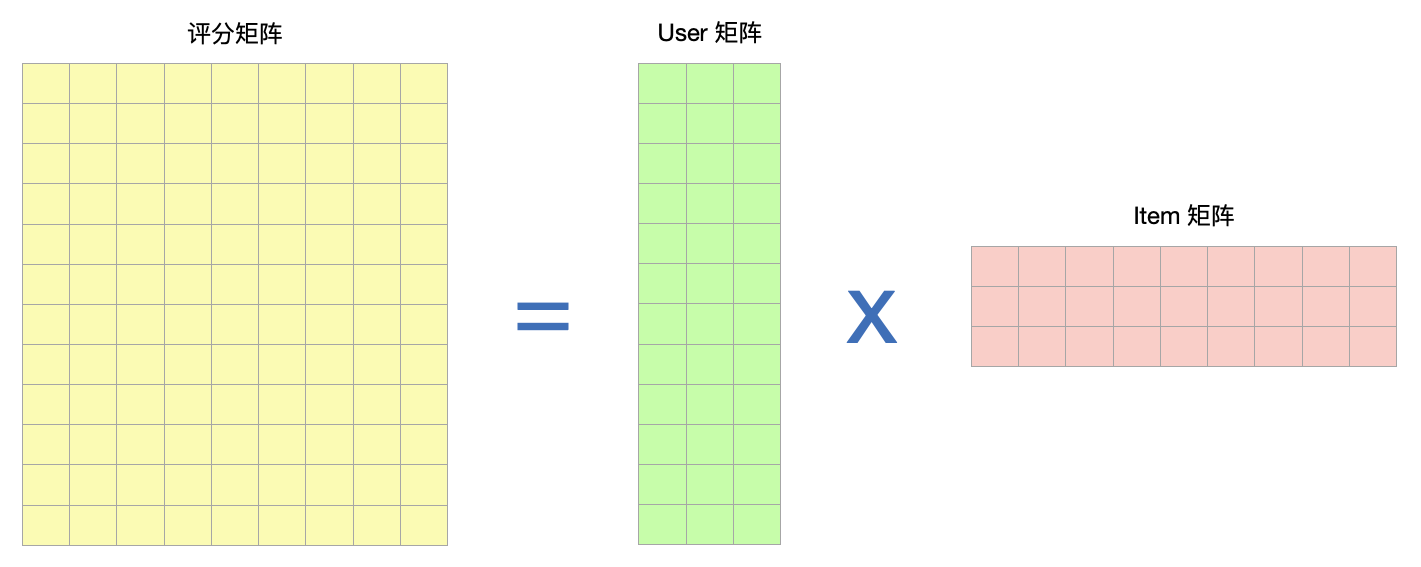
大家还记得这张图把?我们做电影评分,做动态推荐,也就是协同过滤推荐的时候的一张图。
那 Embedding 指某个对象 X 被嵌入到另外一个对象 Y 中,映射 f:X -> Y,它是一种降维方式,转换为维度相同的向量。
比如咱们这个电影评分的矩阵里,矩阵分解中的 User 矩阵,第 i 行可以看成是第 i 个 user 的 Embedding。Item 矩阵中的第 j 列可以看成是对第 j 个 Item 的 Embedding。
最后的最后,咱们再补充说说 Word2Vec 工具的使用。
Word Embedding 就是将 Word 嵌入到一个数学空间里,Word2Vec,就是词嵌入的一种。可以将 sentence 中的 word 转换为固定大小的向量表达(Vector Respresentations), 其中意义相近的词将被映射到向量空间中相近的位置,将带解决的问题转换成单词 word 和文章 doc 的对应关系。
举个例子,大 v 推荐能不能用它?用过微博吧?你关注了某一个人,微博还可以给你推荐其他的一些相关的大 v,怎么做?现在在做 word2vec 我们需要有单词,需要文章,只要你给他很多文章就可以把单词的特点求出来,这样你就可以基于单词做相关单词的推荐。
我们可以用类似的一些原理,大 v => 单词,将每一个用户关注大 v 的顺序 => 文章。
除此以外,商品推荐中,商品可以看成是单词,用户对商品的行为顺序可以看成是文章。这样我们就可以把每个商品去做词嵌入的表达,再基于它去做商品推荐。
那以上这些内容是一些延展顺序,大 v 推荐和商品推荐是在推荐系统里面比较常见的使用场景。Word Embedding 实际上是个思维,不仅仅是做单词的学习,你只要能把它看成单词就可以对内容做推荐。
今天的内容,大家一遍没看懂的要多看几遍,好好消化一下。
24. BI - 一篇文章带你详细理解特征工程核心:Embedding

