27. BI - PageRank 的那些相关算法 - PersonRank, TextRank, EdgeRank
本文为 「茶桁的 AI 秘籍 - BI 篇 第 27 篇」

Hi, 我是茶桁.
之前咱们用两节课的时间来讲了 PageRank, 包括它的起源, 公式以及工具.
并在一个希拉里邮件的案例中用networkx完成了练习.
在上一节课中, 咱们不仅做了案例, 并且说到了 PageRank 模型的影响力,
并且讲了其中一个在社交网络中应用的算法personRank.
除了PersonRank, 还有Textrank,
EdgeRank.
其实, PageRank不仅是一个算法, 而是一种思想.
这个思想还可以用到文本的影响力排序, 边的排序. 这里的边指的是信息流.
大家应该都用过微信朋友圈. 微信朋友圈要做广告推送, 其实每一个朋友圈都是个节点. 微博也是一样, 叫信息流广告.
信息流广告里面怎么样去对有价值内容做排序? 那 PageRank 就很重要,
还有之前给大家讲到的PersonRank.
Textrank 算法
下面, 咱们来看另外一个算法Textrank。
Text就是文本,
如果你要对文本做排序就要找关键词,找到一篇文章中哪些文本最重要。原理也是跟图论的PageRank方法是一样的。
首先, 根据词之间的共现关系构造一个网络。
词和词之间怎么样去连一条边, 是基于它的共现关系。一起出现就叫共现,
一起就是用一个窗口框出来。
比如说 A B C D E, 窗口等于 2, 那就是前后两个叫共现。前后两个在一起, 挨着比较近就会有一条边,这条边会告诉你它是一条无向的有权边。 有权就是它的次数可能是有多次,都需要做个记录,就代表权重的大小。
看一个例子, 比如下面这篇文章

这篇文章可以把单词和单词之间的一些关系按照下图进行一个连接
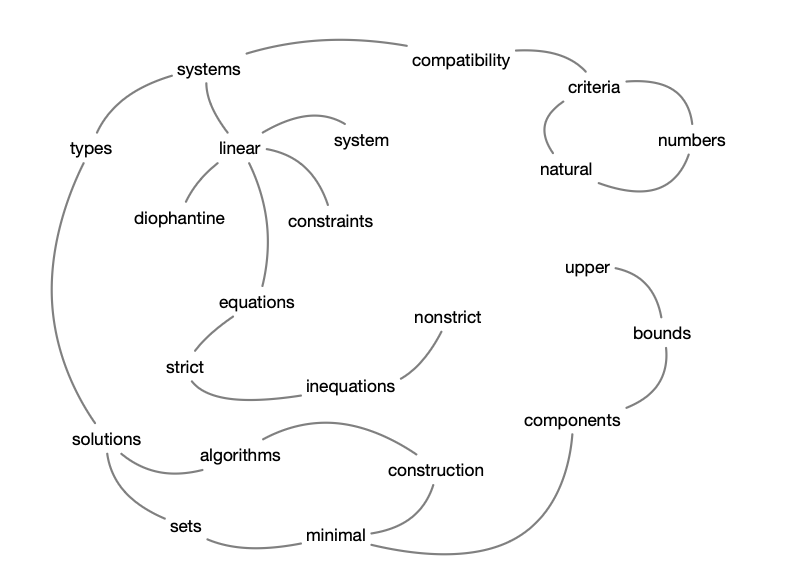
在这里可以看到, 有些单词是没有出现的. 并不是所有单词都要放进去,
所以第一步要去掉stopword. 一些停用词会对文本分析造成干扰,
所以要把这些干扰项的给去掉.
如果不把它去掉最后读出来的关键词基本都是of,
on, the等等.
去掉以后, 假设现在的窗口等于 2.
那capability和system之间就变成一个连接关系,
我们会用一条无向边来去做一条连接.
system和linear也会有条边,
linear和constraints也会有条边.
这样就把这张连接图构建出来了, 前后的 window
是因为设置一个超参数window size = 1.
Textrank的本质就是构造一张图, 按照共现关系来构造.
有了图我们就可以计算影响力, 就可以按照影响力大小来做排序.
分词是要做的最开始的一步, 之后去掉停用词. 另外也可以去获取词性, 就是词的一些属性.
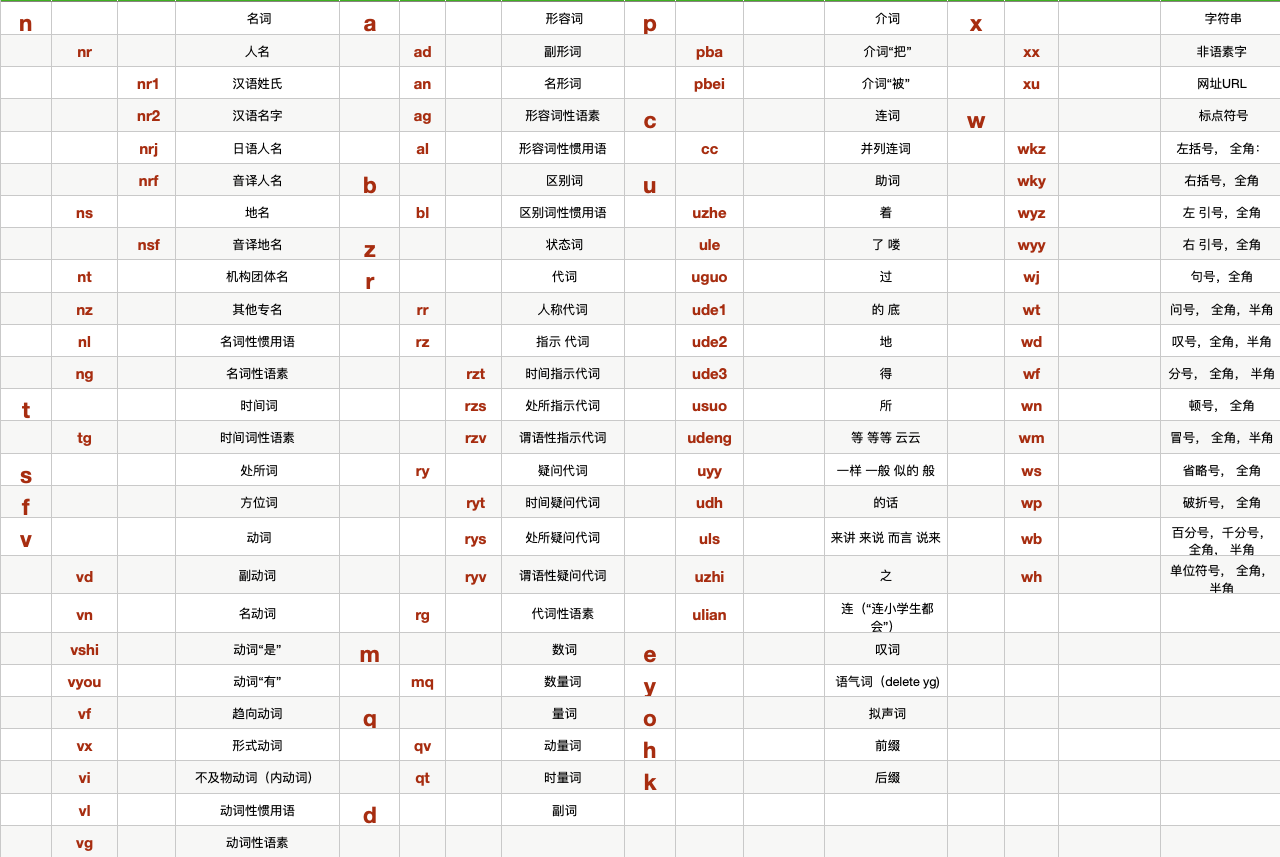
常见的词性, 比如名词, 动词. 这些词性有一张词性表, 这张表格不需要背下来, 可以发现其实每个单词按照不同的词性还可以再做一层过滤.
比较常见的一些词性如名词, 动词, 分别是n和v,
这是它的英文缩写. 人名是nr, 地名是ns.
有了这样一些词性可以去看一看文章中有没有提到一些人, 文章中有没有提到一些地点, 可以按照地点做一个排序.
通过词性可以筛选一些你想要那些关键词的属性, 咱们以一个例子一起去看一看.
4 日,日本政府与驻日美军就支援能登半岛地震灾区进行协调。双方将商议具体的救援办法和开始时间。预计美方将负责运输救援物资和灾民。
比如说这个是今日的一个新闻, 微博热搜上粘贴下来的.
针对这个新闻我们先去做一个jieba.cut, 把句子做了一个分割.
词性可以使用pseg.cut, 直接通过pseg去获取.
1 | |
jieba就可以帮你切分, 得到的是单词和 flag.
可以对应我们上面的那张词性表来看.
所以词性也是可以当成一个要去分析的对象,
那Textrank怎么做呢? Textrank是把它看成一张图,
这个图用的是随机浏览的方式. 随机浏览的计算过程如下面这个公式:
\[ \begin{align*} PR(V_i) = \frac{1-d}{N} + d\sum_{V_j \in In(V_i)} \frac{PR(V_j)}{|Out(V_j)|} \end{align*} \]
Textrank在此基础上有一些变化:
\[ \begin{align*} PR(V_i) = \frac{1-d}{N} + d\sum_{V_j \in In(V_i)} \frac{W_{ij}}{\sum_{V_k\in Out(V_j)}W_{jk}}PR(V_j) \end{align*} \]
\(W_{ij}\)是单词i和j之间的权重,
节点的权重不仅依赖于入度, 还依赖于入度节点的权重.
整个流程首先需要现进行分词和词性标注, 将单词添加到图中. 然后出现在一个窗口中的词形成一条边, 基于 pageRank 原理进行迭代, 默认在 20 到 30 次左右, 这个参数可以自性进行调整. 然后对顶点, 也就是词按照分数进行排序, 可以筛选制定的词性.
所以Textrank就是套了一层PageRank,
只要把单词看成顶点就可以对它做排序.
jieba这个工具里就集成了Textrank的算法,
可以使用它去提取关键词.
1 | |
传入的是一个sentence,topK是要输出的单词的个数,
withWeight是要不要输出权重, 默认是False.
allowPos为是否返回指定类型, 默认就为空.
刚才咱们例子中做完分词了, 接下来咱们继续往后写.
1 | |
我在 allowPOS里输入了n, 也就是名词,
这一段代码打印出来的就都是名词词性的内容. 如果我们删掉这个属性之后,
那输出的就是所有词性的一个 top10 排序. 因为这个句子单词数量并不多,
所以它整个得出来的关键词也并不是很多. 词性筛选可以有多个,
比如说也要动词, 那我们就可以输入 n 和 v:
1 | |
这样就会把所有的名词和动词都做一个过滤.
这个就是整个 Textrank 提取关键词. 学完这个之后,
咱们还记得之前介绍过一个提取关键词的方法, 叫做TF-IDF,
大家应该还没忘吧?
相较于Textrank,
TF-IDF考虑了IDF的情况, 而
Textrank 倾向使用频繁次,
所以效果上TF-IDF会更好一点, 而且效率上也会更高, 因为
Textrank 是基于图的计算, 迭代较慢.
所以在计算关键词的过程中我们实际上用TF-IDF会更多一点.
Textrank的特点除了计算关键词以外,
还能有一个作用叫做关键句, 可以生成摘要.
如果看一篇文章, 这篇文章很长, 可能有三四千字, 没有这么多的时间把文章从头到尾都看完, 就可以让机器帮你找到那些关键的句子.
关键句就是排序, 只要是排序,
一般都会基于PageRank的思路进行. 你对谁排序 谁就是 page.
对句子排序, 比如句子S1 S2 S3, 句子和句子之间就需要有一条边,
边是否相连就代表句子是否相似, 如果两个句子里出现相同的单词个数比较多,
所占的比值比较高就认为这两个句子是相似的, 就可以连一条边.
所以句子之间的相似度有可能并不是前后两个句子. 第 1 个句子和第 100
个句子比较相似, 照样是可以连一条边.
所以边的这个逻辑是按照相似度来去判断的, 这是在关键句的计算过程中.
这样就会把这 100 个句子, 100 个顶点之间的相关性计算出来了.
相关性比较高就会有边了. 有了边, 有了这张图就可以计算它的影响力.
因为只要有图就可以用PageRank的方法,
就可以对sentence做个排序, 关键句就形成了摘要.
你可以提取出来前 10 个句子, 就形成一篇文章的摘要.
它有两个工具, 一个4Keyword,
一个4Sentence:
1 | |
1 | |
TextRank生成摘要的原理其实就是每个句子作为图中的节点,
如果两个句子相似, 则节点之间存在一条无向有权边.
相似度就等于同时出现在两个句子中的单词的个数除以句子中单词个数求对数之和(分母使用对数可以降低长句在相似度计算上的优势.)
为什么这里取了个对数? 前面是出现过相同的单词的个数, 肯定认为两个句子里面都有的单词个数越多就越相似. 后面为什么不直接把单词个数之和作为一个累加?
对数一个特点就是趋势会变得不明显, 之前是线性的关系,
现在变成了一个对数关系. 所以对数会把原来的关系变成的更加平滑一点,
相对来说会更合理一些.
所以在文本计算很多特征值的时候都在分母里面求一个对数.
在TF-IDF的中也是同样使用了对数作为分母.
EdgeRank 算法
除了Textrank,
其他的一些方法也借鉴了Textrank的原理. 微博借鉴的就是
Facebook 的信息流推荐方法, EdgeRank算法. 最早就是 Facebook
来提出来的.
很多的一些大厂愿意出一些开源成果, 会把它写成一些文章, 你能看到具体算法的一些描述. 但 Facebook 没有写, 反而申请了一个专利. 原因是因为它跟钱是非常相关的.
互联网公司信息流的广告价值非常大, 在 Facebook
里面主要用的是feed信息流来做广告,
微博也是通过信息流来去做一些广告. 所以它的价值会很大,
那它就不能把信息流排序的原理告诉你.
举个例子, 百度如果把网页排名的原理, 把所有的过程都告诉你, 那它的排名就没有那么好的效果了. 因为很多商家为了追求排名会做很多的优化, 这个优化有可能是过度优化, 作为平台方还要再去改进方法去改变它. 如果再去公布出来, 还会有人再做优化, 会被钻空子.
因此EdgeRank这个方法是一个商业化的方法, 没有写文章,
转而申请了专利.
但是我们也可以知道确实存在这样的方法, 微博借鉴了这个思想做了一套自己的算法.
2017 年的年底, 微博采用EdgeRank的这个方法,
经过调整之后遭到很多大 v 的抗议. 在 2017 年年底确实发现了一些事件,
原来有 100 万的粉丝, 阅读量可能有几十万.现在阅读量不到 10 万,
甚至可能不到 1 万.
因为微博调整了算法,对信息流的推荐也不是所有人都能看得到.
以前品牌方做官方微博会觉得微博上搞搞活动, 很多粉丝就关注你了.
这样以后做营销就很省钱, 这是品牌方的一个愿景. 确实,
很多品牌方也是抱着这样一个目的去开启他的官方微博.
很多品牌经常会搞一些活动, 转发抽奖, @三个好友,
如果关注就有机会完成抽奖.
他的作用是瞬间吸引大量的粉丝去关注他, 这样一些关注得来的粉丝有很多就是为了奖品来的, 他们其实并不关心微博实际发生什么内容, 只是你现在有了一个抽奖活动我们可以去参与一下, 质量并不高.
如果你的粉丝有 100 万, 这 100 万又不是那种亲密的粉丝, 你再去发广告的时候可能我并不想看.
微博采用的EdgeRank算法就是是基于了以下的三个维度: -
粉丝亲密度 - 内容质量 - 原创程度
粉丝亲密度怎么衡量? 如果一个粉丝在你的官方微博下面经常评论和互动就认为亲密度是高的.
第二个是内容质量, 如果一个微博发的内容质量比较高就可以更多的去做一些推荐.
第三是原创程度, 如果是原创的也可能会推, 增加推荐的一个指数.
因此, 它的排序是基于三个维度来进行的. 假设你是通过转发抽奖这种方式, 粉丝亲密度肯定不高, 内容质量也不高, 这样的一些行为其实在粉丝列表里面, 信息流里面有可能就出现不了. 不是不出现, 只不过在众多的信息流里面可能排名靠后, 可能就降低了出现的概率.
这些方法都是商业化的方法, 所以在信息流的推荐过程中只要存在排名就可以采用它来去做个排序, 把更有价值的内容推荐出来.
微博采用这种方式可谓是一举两得. 内容质量得到提升, 用户满意度提升.
商家以前愿景是不需要买微博广告了, 因为粉丝都关注我,
粉丝就都能看到这个广告. 后来发现并不是这样, 还有很多粉丝看不到,
那怎么办? 如果官方品牌想要做推广可能还会买一些微博流量,
有可能是粉丝通之类的产品. 跟粉丝之间更通顺一些,
买他信息流的推荐的位置. 这样就把那些想要做广告和质量好的人做了一个区分,
这也是非常聪明的一种做法.
总的来说, 我们讲了这么多的Rank,
其鼻祖都是PageRank, 都是做网页影响力的排序.
不管你做TextRank还是做信息流的EdgeRank,
还是给个人去做推荐的别的什么 Rank,
都是来自于十大经典机器学习PageRank.
这个模型的原理也并不复杂, 但是影响力非常深远. 因为它有很多改进型的模型和相关衍生的模型.
PageRank可以看成两个关键词, 一个关键词是图,
一个关键词是影响力. 图就是数据存储的格式,
数据是图的表达. 业务场景输出的是影响力的排序,
所以要去思考能不能用PageRank也是从这两点来进行出发的.
如果数据是一个图, 如果要做的是影响力排序,
那么在用的方法就可以采用PageRank.
讲了这些模型, 我们要思考的如何讲工程转化为模型,
其实就是能不能去转化成图和影响力排序.
关联性就是能否转化为图,
类似Word Embedding中的word和sentence.
需求点是影响力排序,
item embedding相似度计算.
修复Textrank4zh兼容性
本文最后还有一点是关于textrank4zh这个工具的内容,
解决使用过程中的一些兼容性.
使用Textrank4zh这个工具需要注意一下,
其中的源代码需要进行修改. 因为
networkx目前已经是到了3.2.1的版本,
其中from_numpy_matrix也在 2.6 版本之后就不再使用了,
具体可以看这里:https://github.com/networkx/networkx/pull/4238.
在使用过程中我们会收到如下报错:
1 | |
所以这里需要进行一个修改,
转而使用from_numpy_array来进行替代.
进入Textrank4zh的源代码中, 找到
util.py这个文件, 搜索nx.from_numpy_matrix,
然后使用from_numpy_array将其替换, 应该是有两个个地方.
替换完成后就 OK 了,
否则程序会报错:AttributeError: module 'networkx' has no attribute 'from_numpy_matrix'.
当然, 如果你的 Python 环境内安装的是 2.5 或者 2.6 版本的
networkx那还是可以正常使用的, 2.6
版本应该会收到一个警告.
我拉取了原作者乐天的源代码仓库(https://github.com/letiantian/Textrank4ZH)并进行了修改,
Fork 地址为:https://github.com/hivandu/Textrank4ZH. 你可以将代码 clone
到自己的 Python 环境内.
27. BI - PageRank 的那些相关算法 - PersonRank, TextRank, EdgeRank
https://hivan.me/27. BI - PageRank 的那些相关算法 - PersonRank, TextRank, EdgeRank/

